How ScyllaDB’s Trie-Based Index Delivers Up to 3X More Throughput
By transitioning from separate summary and index files to a prefix tree, we optimized cache efficiency, reduced disk I/O, and reduced memory overhead Trie-based SSTable index format was added in ScyllaDB 2025.4. Since then, it has evolved and matured to become the default index format in ScyllaDB 2026.2. In this post, we deep dive into the format change, present its pros and cons, and show our latest benchmark results of the legacy vs. Trie index formats. For benchmarking, we chose four different read workloads that would benefit from the Trie index format in different degrees. For all four, Trie indexes demonstrated better performance. They achieved 20% to 230% higher throughput and 31% to 63% lower latency compared to legacy indexes. The impact of Trie index on the write path is negligible. Note that for use cases with either very low cache usage or 100% row-cache hit rate, the performance gain is expected to be lower. However, these use cases are unlikely in production. Trie Index Usage in ScyllaDB Before explaining the new format, we will cover the legacy index format and its challenges. Legacy Three-Layer Lookup (me/md format) Until ScyllaDB 2026.2 the default storage format was the SSTable version md and me. Every SSTable lookup in the me/md format traverses three or four structures:Summary.db
(entirely in RAM) Binary search in Index.db Sequential
read in Data.db Both the partition index and the
clustering-row index are stored in Index.db. The
partition index is partially represented in memory by the sampled
Summary.db, while the clustering-row index exists as a
promoted index for large partitions. ┌──────── MEMORY
──────────────────────────────┐ │ │ │ Summary.db (entirely in RAM)
│ │ ───────────────────────────── │ │ Sampled at ~1 byte per ~2000
bytes of │ │ Data.db │ │ │ │ "aardvark" → Index.db byte 0 │ │
"kangaroo" → Index.db byte 1,048,576 │ │ "platypus" → Index.db byte
2,097,152 │ │ "zebra" → Index.db byte 3,145,728 │ │ │
└──────────────────┬───────────────────────────┘ │ binary search →
window in Index.db │ ▼ ┌──────── DISK
────────────────────────────────┐ │ │ │ Index.db │ │ ───────── │ │
"kangaroo" → Data.db: 4,096,000 │ │ "koala" → Data.db: 4,097,280 │
│ "kookaburra" → Data.db: 4,098,560 │ │ "lemur" → Data.db:
4,099,840 ← found │ │ ... (up to ~800 entries per 1 MB scan) │ │ │
└──────────────────┬───────────────────────────┘ │ 1 seek +
sequential read │ ▼ ┌──────── DISK
────────────────────────────────┐ │ Data.db │ │ <partition
data> │ └──────────────────────────────────────────────┘
For partitions containing enough clustering rows, a fourth
structure is involved: Index.db entry for a large partition
┌──────────────────────────────────────────┐ │ partition key →
Data.db offset │ │ promoted_index (flat list of CK blocks) │ │
block 0: ck_start="aaa", ck_end="azz" │ │ block 1: ck_start="baa",
ck_end="bzz" │ │ ... │ │ block N: ck_start=..., ck_end=... │ │
offsets[0..N] ← binary search here │
└──────────────────────────────────────────┘ The New Trie
Index Format The Trie index (#25626)
replaces Summary.db + Index.db with a
single on-disk prefix
tree. The storage format is compatible with Apache Cassandra’s
BTI (Big Trie Index) format, implemented using ScyllaDB’s Seastar
architecture. Trie indexes are used for both partition indexes and
clustering key indexes. What Is a Trie? A trie (prefix tree) stores
keys character-by-character. Shared prefixes occupy a single path,
eliminating redundancy: Keys: "kangaroo", "koala",
"kookaburra", "lemur", "lion" [root] / \ 'k' 'l' | | [k] [l] / \ /
\ 'a' 'o''e' 'i' | | | | 'n' [o]'m' 'i' | / \ | | 'g''a' 'o''u' 'o'
| | | | | 'a''l' 'k''r' 'n' | | | * 'r''a' 'a' * = leaf node | * |
(payload: Data.db offset) 'o' 'b' | | 'o' 'u' * | 'r' | 'r' | 'a' *
"k", "ko", "koo" — shared prefixes stored ONCE New SSTable
Files The ms/mt format replaces Summary.db and
Index.db with two purpose-built files: SSTable
(ms format) ├── Data.db │ unchanged — partition and row data, │
same binary layout as me/md │ ├── Partitions.db ← NEW │ Trie index:
│ partition key → Data.db offset │ (small partitions) │ partition
key → Rows.db offset │ (large partitions) │ │ ┌── Page 0 (4,096
bytes) ───────┐ │ │ trie root node [1] │ │ │ + children (fan-out ≤
256) │ │ │ + their children (packed) │ │
└───────────────────────────────┘ │ ┌── Page 1 (4,096 bytes)
───────┐ │ │ subtree for keys 'a'–'g' │ │
└───────────────────────────────┘ │ ... │ ┌── Footer
─────────────────────┐ │ │ first_key (raw bytes) │ │ │ last_key
(raw bytes) │ │ │ partition_count (uint64) │ │ │ trie_root_pos
(uint64) │ │ └───────────────────────────────┘ │ ├── Rows.db ← NEW
│ Per-partition clustering-key │ tries, concatenated. │ Each
sub-trie: │ clustering key → byte-offset │ within partition │
(replaces flat "promoted index" │ in Index.db) │ ├── Filter.db
bloom filter — unchanged ├── Statistics.db statistics — unchanged
└── Scylla.db ScyllaDB metadata — unchanged [1] Parent nodes
are always written after their child nodes. Parents point to
children, so child positions must be known before parents are
written. How a Partition Lookup Works Query: SELECT * FROM
orders WHERE order_id = 'ORD-20240611-98765'
┌─────────────────────────────────────────┐ │ Step 1 — Key
Translation │ │ │ │ 'ORD-20240611-98765' │ │ ↓
bti_key_translation.cc │ │ comparable byte sequence │ │
(lexicographic order matches │ │ CQL semantic order) │
└──────────────────┬──────────────────────┘ │
┌──────────────────▼──────────────────────┐ │ Step 2 — Trie
Traversal │ │ in Partitions.db │ │ │ │ Read root page (4 KB) │ │ ←
usually in OS page cache │ │ │ │ [root] ──'O'──> [node] (page 0)
│ │ [node] ──'R'──> [node] (page 0) │ │ [node] ──'D'──>
[node] (fetch page 1) │ │ [node] ──'-'──> [node] (page 1) │ │
... │ │ [leaf] payload = Data.db or │ │ Rows.db pos 2,097,152 │ │ │
│ Typical: 2–6 page fetches. │ │ Top pages cached → often 0–1 disk
I/Os │ └──────────────────┬──────────────────────┘ │
┌──────────────────▼──────────────────────┐ │ Step 3 — Read Data.db
│ │ Seek to offset 2,097,152 │ │ → read partition header │ │ For
large partitions: read Rows.db │
└──────────────────┬──────────────────────┘ │ (range/clustering
queries only) ┌──────────────────▼──────────────────────┐ │ Step 4
— Read Data.db at position │ │ returned from index │
└─────────────────────────────────────────┘ Page Layout:
Packing Parent and Children Together The most critical write-time
optimization is ensuring that a node and its children land on the
same 4 KB page. This means an entire trie
neighborhood is readable in a single I/O, even on the first (cold)
access. ┌──────── 4,096-byte page ────────────────┐ │ │ │ [A]
──'p'──> [B] ──'p'──> [C] │ │ │ │ │ │ └──'r'──> [D]
├──'l'──>[E]* │ │ │ │ │ └──'y'──>[F]* │ │ │ │ (* = leaf node
with payload) │ │ (padding bytes to align next subtree │ │ to page
boundary) │ └─────────────────────────────────────────┘ trie_writer
algorithm (trie_writer.hh): 1. Maintain rightmost path root →
current node (_stack) 2. On each new key: branch off rightmost
path, add new nodes 3. Accumulate nodes until a finished subtree
exceeds a page 4. Flush child subtrees with padding so each subtree
fits within one page ScyllaDB vs. Cassandra reference impl:
Cassandra: one character per node ScyllaDB: characters grouped into
"chains" (up to 300 bytes) → dramatically faster writes for long
keys, same read-side page structure Old vs. New:
Side-by-Side Summary Legacy me/md Trie ms/mt On-disk
files Summary.db + Index.db
Partitions.db + Rows.db In-memory
component Summary (always loaded, never evicted) None.
Trie top-nodes live in OS page cache (evictable) Index
structure Flat sorted list Prefix tree Partition
lookup (cold cache) Binary search in summary (RAM) + scan
of Index.db window Trie traversal byte-by-byte: O(key_length) page
reads Key storage Full key per entry Shared
prefixes stored once Clustering key lookup Flat
promoted-index list (binary search) Sub-trie in
Rows.db (trie traversal) Benchmark Results The
following table shows the key results, measured at client-side P99
≤ 10 ms on a 3-node AWS production-class cluster. All tests were
run on 3 × i8g.2xlarge instances, each on a different zone, with
Replication Factor (RF) of 3. For a full description of the test
cases and setup, see the Appendix below. Test case Legacy (me)
Throughput Legacy (me) P99 Trie (ms) Throughput Trie (ms) P99
Throughput gain Test 1: Typical (~20% row cache) 130k ops/s 5.1 ms
170k ops/s 1.9 ms +31% Test 2: Key / Value 90k
ops/s 5.2 ms 300k ops/s 3.6 ms +233% Test 3: Large
Partitions 23k ops/s 7.7 ms 37k ops/s 4.6 ms +61%
Test 4: Long shared clustering key prefixes 22k ops/s 5.4 ms 38k
ops/s 3.3 ms +73% Discussion: Why Trie Indexes
Improve Performance, and When to Use Them ScyllaDB CTO Avi Kivity
has mentioned three reasons why Trie indexes improve performance:
Improved cacheability: the index is denser, so it
is more likely to fit in cache, requiring no I/O for the index
itself. Fewer I/O operations after cache miss: if
the index is not in cache, fewer I/O operations are required to
fetch it since the index is more compact and shallower. This is
especially true for large partitions, often seen in materialized
view workloads. CPU efficiency: less CPU is needed
to process the index during reads. A possible downside is that more
CPU is needed to create the index during memtable flush and
compaction. However, this is more than offset by the read-side
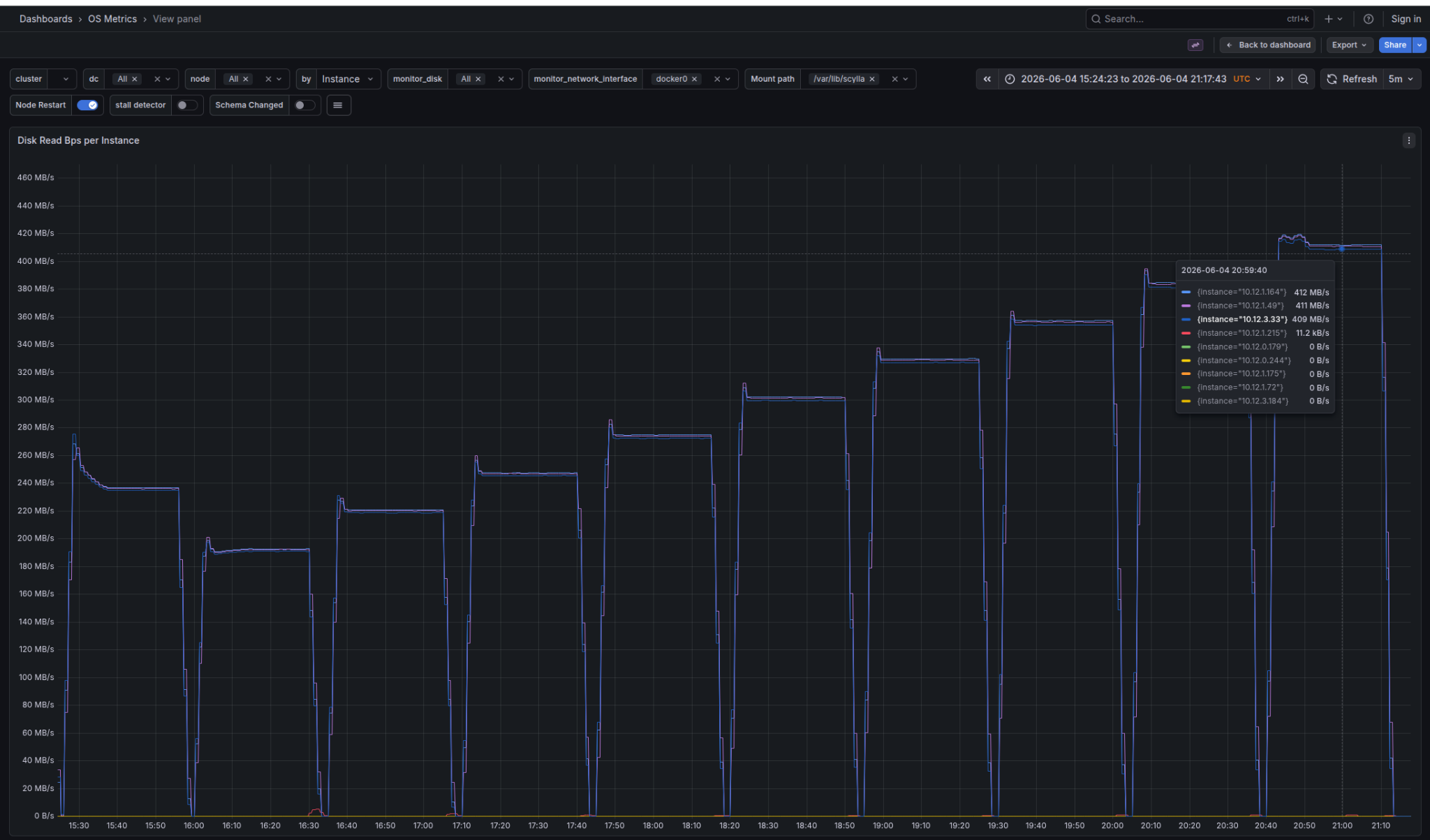
advantages. For proof of Avi’s first point, see the Disk Read
panels from ScyllaDB Monitoring’s OS metric dashboard for legacy
vs. Trie index format. Each step represents increasing workload
throughput. For the first load, using the same throughput, Disk
Reads for legacy indexes is ~240 MB/s; for Trie indexes, it is ~33
MB/s. The Trie index consumes only ~1/7th of the storage bandwidth.
Note
that the Trie index has a negligible effect for 100% cache hit rate
or 0% cache hit rate workloads. For both, the in-memory index
representation is irrelevant. Write workload is also only
marginally affected by the index format change. Summary ScyllaDB
2026.2 has adopted a Trie-based index format as its new default,
replacing the legacy index structure to significantly enhance read
path performance. By transitioning from separate summary and index
files to a prefix tree, this design optimizes cache efficiency,
reduces disk I/O, and reduces memory overhead. Benchmarks indicate
that this architectural change delivers throughput improvements
ranging up to 3x across various workloads, offering a more scalable
and efficient solution than the legacy index format. As
always, actual results depend on your workload. To evaluate the
gain of Trie index, we highly recommend testing it yourself with
the latest ScyllaDB releases. Appendix: The Full Test
Setup All tests compare me (legacy) vs. ms (trie) format on
identical code, hardware, and dataset. Metric: maximum
throughput (ops/s) at which client-side P99 latency stays below 10
ms. Hardware and Infrastructure {kind=link}
{kind=link}
Component
Specification ────────────────────────────────────────── Cloud
provider AWS us-east-1 DB nodes i8g.2xlarge × 3, RF=3, 3 racks
Loaders (normal) c7i.4xlarge × 4 (Tests 1, 3) Loaders (large)
c7i.4xlarge × 3 (Tests 2, 4) Row cache ~20% of dataset Kernel
7.0.0-1006-aws SSTable formats me (legacy) vs ms (trie)
────────────────────────────────────────── Software Versions
Component Version ScyllaDB 2026.3.0~dev cassandra-stress 3.20.6
latte 0.48.0-scylladb Java driver 3.11.5.14 Rust driver (latte)
1.6.0 Python driver 3.29.10 Test 1: Typical (~20% Row Cache)
Description: Standard cassandra-stress read
workload with ~20% row cache. Closest analogue to a general
production workload. Schema and dataset:
CREATE TABLE keyspace1.standard1 ( key blob PRIMARY KEY, C0
blob, C1 blob, C2 blob, C3 blob, C4 blob ); -- 5 columns × 256
bytes ≈ 1,280 bytes/row -- 650,000,004 rows -- (written with CL=ALL
across 4 loaders) Workload parameters:
Stress tool: cassandra-stress Consistency: QUORUM Access:
Sequential on 2 loaders, Gaussian on 2 loaders Threads: 620 total
Throttle: 70k–250k ops/s in 10k steps, 30 min per step SCT config:
test-cases/trie/ perf-steps-neutral.yaml
Builds: Format ScyllaDB revision Build date Build
ID me 1fdd379bf99c 2026-06-03 8c9256ba ms
1fdd379bf99c 2026-06-03 8c9256ba
Results: Legacy me Trie ms Max Throughput 130k
ops/s 170k ops/s P99 Latency 6.28 ms 3.19 ms Throughput
gain — +31% Latency at
saturation 6.28 ms 3.19 ms (−49%) Note:
Even at the same 130k ops/s, Trie P99 is 3.19 ms vs 6.28 ms — half
the latency, with substantial headroom before the 10ms ceiling.
Test 2: Key / Value Description: Deliberately
favorable for the trie. Schema has only a partition key with no
clustering columns. Tiny rows (~8 bytes payload) mean extremely
high partition density. The trie’s prefix compression yields much
higher effective cache density than the legacy flat list.
Schema and dataset: CREATE TABLE
trie_test.fav ( key blob PRIMARY KEY, col blob -- FIXED(1024) in
stress profile ); -- ~8 bytes/row effective (key-only access) --
650,000,004 rows Workload parameters:
Stress tool: cassandra-stress (custom profile) Throttle: me:
70k–100k ops/s ms: 230k–350k ops/s (non-overlapping by design — me
saturates far below ms) Step duration: 30 minutes SCT config:
test-cases/trie/ perf-steps-fav.yaml
Builds: Format ScyllaDB revision Build date Build
ID me 1fdd379bf99c 2026-06-03 8c9256ba ms
d8de7268e7f4 2026-06-05 b6e8613d
Results: Legacy me Trie ms Max Throughput 90k
ops/s >280k ops/s P99 Latency 6.12 ms 4.50 ms Throughput
gain — >+211% The trie can serve 3×
the request rate at lower latency because the same OS page cache
budget covers 3× more trie top-nodes than the equivalent
Index.db window. Test 3: Large Partitions
Description: Each partition holds 460,000 rows
with a large clustering key. With only ~100 total partitions,
per-shard throughput (not index access) is the bottleneck. Tests
the trie row index (Rows.db) rather than the partition
index. Schema and dataset: CREATE TABLE
trie_test.large ( pk blob, ck blob, value blob, PRIMARY KEY (pk,
ck) ); -- 46M total rows -- 460,000 rows per partition, ~100
partitions -- Accessed via: latte large-partition.rn
Workload parameters: Stress tool: latte
0.48.0-scylladb (large-partition.rn) Threads: 1 Throttle: 10k–70k
ops/s in 10k steps, 30 min per step SCT config: test-cases/trie/
perf-steps-large.yaml Loaders: 3 × c7i.4xlarge
Builds: Format ScyllaDB revision Build date Build
ID me e5b4f43ec1c8 2026-06-02 c32c9fc9 ms
e5b4f43ec1c8 2026-06-02 c32c9fc9
Results: Legacy me Trie ms Max Throughput ~19,998
ops/s ~29,998 ops/s P99 Latency 2.87 ms 3.80 ms Saturation point
~24k (at 30k target) ~37k (at 40k target) Throughput
gain — +50% Test 4: Long Shared
Clustering Key Prefixes Description: The worst
case for the trie. Clustering keys are 2048 bytes long with a long
common prefix — only the final bytes differ. This maximizes trie
depth, erodes prefix sharing, and inflates node fan-out near the
top. Same schema as Large Partitions with 10× fewer rows per
partition (46,000 vs 460,000). Schema and dataset:
CREATE TABLE trie_test.unfav ( pk blob, -- 4 bytes ck blob,
-- 2048 bytes, long shared prefix value blob, -- 1024 bytes PRIMARY
KEY (pk, ck) ); -- 46M total rows -- 46,000 rows per partition,
~1,000 partitions -- Accessed via: latte unfavorable.rn
Workload parameters: Stress tool: latte
0.48.0-scylladb (unfavorable.rn) Threads: 1 Throttle: 10k–80k ops/s
in 10k steps, 30 min per step SCT config: test-cases/trie/
perf-steps-unfav.yaml Loaders: 3 × c7i.4xlarge
Builds: Format ScyllaDB revision Build date Build
ID me a0e160db8a7d 2026-06-04 f1e189b2 ms
a0e160db8a7d 2026-06-04 f1e189b2 ScyllaDB 2026.2: DynamoDB Streams and Vector Search, Trie Indexes, and Strongly Consistent Tables
ScyllaDB 2026.2 brings a combination of GA new features, exciting experimental features, and multiple stability and external use case improvements. The updates include: DynamoDB compatible API (Alternator) enhancements: DynamoDB compatible Streams and Vector Search extension. Performance and Stability: Trie index performance improvement, and streamlining connection storm handling. ScyllaDB Cloud: New Private Link connectivity feature and Vector Search integrations (LangChain, LlamaIndex, Spring AI, Agno, and more). Experimental features: Strongly Consistent Tables and vNode-to-Tablet online migration. 2026.2 is more stable, works faster, and better than any past release. You are encouraged to upgrade to it, and use it for any new deployment. For the full release notes, see this forum post. DynamoDB compatible API (Alternator) enhancements Alternator is a native DynamoDB-compatible API on ScyllaDB. ScyllaDB 2026.2 includes two major additions to that API: DynamoDB Streams compatibility and a Vector Search extension. Streams are Generally Available Alternator Streams, ScyllaDB’s DynamoDB Streams-compatible change data capture interface, is now Generally Available (GA). Applications can capture ordered item-level changes from Alternator tables for event-driven architectures, CDC pipelines, and replication workflows. Vector Search Extension A new extension to the Amazon DynamoDB API allows you to use Semantic Vector Search directly on your data. For users in the DynamoDB environment, implementing vector search has been overly complicated. Amazon’s “Zero ETL” forces a dual-service approach (managing both DynamoDB and OpenSearch) and requires using two separate APIs just for Vector Semantic Search queries. ScyllaDB eliminated the heavy lifting by integrating vector search capabilities into Alternator, our DynamoDB-compatible API. This gives DynamoDB users high-performance similarity search within their familiar API, without the need for extra clusters or constant API context-switching. Vector Search is available in ScyllaDB Cloud. Performance: Trie index by default The Trie-based SSTable index format was added in ScyllaDB 2025.4. Since then it has evolved and matured to become the default index format in ScyllaDB 2026.2. The Trie index format increases throughput by up to x3 with lower latency compared to legacy index formats. To read more, see our upcoming blog post, How ScyllaDB’s Trie-Based Index Delivers Up to 3X More Throughput. Stability: Connection Storm Mitigation A connection storm is the result of thousands of applications reconnecting to the cluster after a node restart or a network issue. This issue is rare. But, when it happens, it’s important that it doesn’t cause latency to spike. In 2026.2, we implemented multiple mechanisms to mitigate this effect. Some of them are: Coordinator side connection throttling Unified authentication and authorization cache Improved password hashing Using a lower default service level Replica-Side Load Shedding As shown below, the effect is dramatic. From a P99 of 5 seconds during a connection storm (after a node restart) to 3.5 milliseconds. For more details, see our upcoming blog post, Cutting P99 Latency 1000X During Connection Storms by Hardening ScyllaDB Admission Controls. ScyllaDB Cloud ScyllaDB continues to expand its Vector Search capabilities with integrations to popular tools like LangChain, LlamaIndex, Spring AI, Agno and more. For more details, see our upcoming blog post, Build Durable Chat Memory for RAG Using ScyllaDB and LangChain. New experimental features Strong Consistency: Raft Group per Tablet ScyllaDB has been using the Raft consensus algorithm for metadata like cluster topology and data distribution (Tablets) for years now. In this release, ScyllaDB started using Raft for data consistency as well. You can now create a globally consistent Keyspace, and enjoy strong consistency – with performance that’s very close to eventual consistency, and superior to the existing LWT approach. You can read more about this in Riding the Raft to Strong Consistency in ScyllaDB. vNodes to Tablets Migration Tablets, ScyllaDB’s new dynamic algorithm for data distribution, powers ScyllaDB’s extreme elasticity. With 2026.1, tablets achieved full feature parity and became recommended for all new clusters. But what about exiting production clusters? In 2026.2, ScyllaDB provides a zero downtime migration from legacy vNode to Tablets, with minimal resource usage. See Migrate a Keyspace from Vnodes to Tablets in the ScyllaDB documentation for details. Want to use one of the experimental features? See the documentation for details on how to enable them, or contact the ScyllaDB Cloud support team.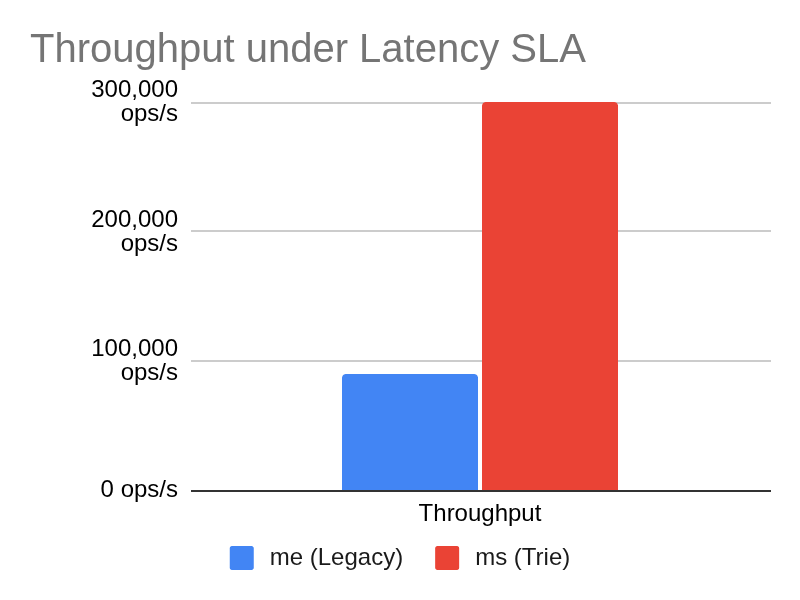{kind=link}
{kind=link}
{kind=link}
Using Salting to Lower Latency for Large Blobs in ScyllaDB
A modified salting technique that cuts P99 write latency 22x for large blobs Storing huge blobs in any database has always been, and still is, very challenging. Large allocations required for storing, reading, compacting, and repairing such cells always create significant pressure on the memory allocation sub-system. In addition, receiving a write request or sending a read response with a huge payload on a shared connection creates a “head of line” issue impacting the latency of other requests. This is true for every database! Consequently, by splitting the blob into smaller chunks and processing them in parallel, we can achieve latencies comparable to a single chunk read/write operation. Naturally, when all your data consists of huge blobs, you are probably not going to use CQL or SQL databases to store them. You will use S3-like storage for blobs and will use CQL/SQL DB to store references to those blobs. However, if your data is mostly reasonably small but has a small part of the population that are huge blobs, you may want to be able to serve both small and large blobs from the same database. While working with ScyllaDB, we found that a modified salting technique can address the latency impact of storing large blobs. In this post, we present that salting technique, then explain when/how to apply it. Background: Large Blobs in ScyllaDB For a better idea of how storing large blobs impacts performance, let’s look at an example. In our testing of ScyllaDB version 2026.1.1 with cassandra-stress tool, we observed that writing key-value rows with a 60MB blob cell results in an average latency of about 568ms and P99 latencies of 1.4s. In contrast, writing K/V data of 1MB yields an average latency of 2.2ms, with a P99 of approximately 4.5ms. When writing 60MB cells, ScyllaDB could not go any faster because its memory management system was totally saturated. Below are the results of the 60MB cell test (with a single i8g.4xlarge node): Results:Op rate : 18 op/s [WRITE: 18 op/s]
Partition rate : 18 pk/s [WRITE: 18 pk/s] Row rate : 18 row/s
[WRITE: 18 row/s] Latency mean : 567.6 ms [WRITE: 567.6 ms] Latency
median : 497.0 ms [WRITE: 497.0 ms] Latency 95th percentile :
1087.4 ms [WRITE: 1,087.4 ms] Latency 99th percentile : 1436.5 ms
[WRITE: 1,436.5 ms] Latency 99.9th percentile : 1874.9 ms [WRITE:
1,874.9 ms] Latency max : 1995.4 ms [WRITE: 1,995.4 ms] Total
partitions : 1,000 [WRITE: 1,000] Total errors : 0 [WRITE: 0] Total
GC count : 0 Total GC memory : 0.000 KiB Total GC time : 0.0
seconds Avg GC time : NaN ms StdDev GC time : 0.0 ms Total
operation time : 00:00:55 And here are the results of writes
of 1MB cells with the same rate byte-to-byte with the 60MB
execution above: Op rate : 1,061 op/s [WRITE: 1,080 op/s]
Partition rate : 1,061 pk/s [WRITE: 1,080 pk/s] Row rate : 1,061
row/s [WRITE: 1,080 row/s] Latency mean : 2.2 ms [WRITE: 2.2 ms]
Latency median : 2.0 ms [WRITE: 2.0 ms] Latency 95th percentile :
2.8 ms [WRITE: 2.8 ms] Latency 99th percentile : 4.5 ms [WRITE: 4.5
ms] Latency 99.9th percentile : 15.0 ms [WRITE: 15.0 ms] Latency
max : 41.6 ms [WRITE: 41.6 ms] Total partitions : 60,000 [WRITE:
60,000] Total errors : 0 [WRITE: 0] Total GC count : 0 Total GC
memory : 0.000 KiB Total GC time : 0.0 seconds Avg GC time : NaN ms
StdDev GC time : 0.0 ms Total operation time : 00:00:56 The
60MB blob results are suboptimal for high-performance requirements.
However, 1MB results show that if we can split the blob into
smaller chunks and write/read them in parallel we can achieve
latencies close to a single chunk read/write operation. Perhaps
salting can help us achieve this? Classic Salting Technique The
classic “salting” technique, used to break down large partitions
consisting of too many rows, introduces an additional “salt” column
to the partition key. It selects a random value from a known range
(e.g., an integer between 0 and 99) to store the next row. This
will distribute what once was a single large partition for a key
KEY1 into 100 smaller partitions with partition keys (KEY1, 0),
(KEY1, 1) …, (KEY1, 99) each of about 1/100 the size of the
original one. The primary drawback of this technique for large
partitions is the necessity of using “salting” for every row, as
the system does not inherently know if a row belongs to a large
partition. Consequently, reading data for any original key KEYn
requires reading all 100 partitions (KEYn, k), where k=0, 1, …, 99.
And this may be very wasteful because large partitions normally
represent a very small part of the total partition population.
Similarly, large blobs typically represent only a small fraction of
the total blob population. Another “weak spot” of the classic
“salting” is that you can’t reduce the SALT cardinality — you can
only increase it. This means that if the size of your large
partitions got smaller, you would still need to use the same “salt”
cardinality you already used before. Modified Salting Technique for
Storing Blobs We found that improving the original “salting”
algorithm for a blob case can eliminate both of those drawbacks.
Let’s look at how we modified that classic salting technique.
Schema Let’s assume that the original table schema is as follows:
CREATE TABLE keyspace1.standard1 ( key blob, value blob,
PRIMARY KEY (key) ) For our algorithm, we modify it to:
CREATE TABLE keyspace1.standard1 ( key blob, salt int,
chunk_id int, chunk blob, total_chunks int, salt_cardinality int
PRIMARY KEY ((key, salt), chunk_id) ) Algorithm Write On a
write path, we are going to store the used “max_salt”
(salt_cardinality) and the total number of chunks
(total_chunks) in every row in addition to the rest of the
chunk-specific data for simplicity. If you want to optimize the
storage to a bitter end, you can store salt_cardinality
and total_chunks only in the “metadata row” (see below).
def write_key_blob(key, blob, max_salt=100,
max_chunk_size=4096): # Split blob into chunks; last chunk may be
smaller split_blob_chunks: List[bytes] = split_blob(blob,
max_chunk_size) num_chunks = len(split_blob_chunks)
salted_partition_chunks = [[]] * min(num_chunks, max_salt) for
chunk_id, chunk in enumerate(split_blob_chunks):
salted_partition_chunks[chunk_id % max_salt].append( (chunk_id,
chunk) ) for salt, chunks in enumerate(salted_partition_chunks): #
Inserts salted partition in one or a few UNLOGGED BATCHes
insert_async_batch( key=key, salt=salt, chunks=chunks,
total_chunks=num_chunks, salt_cardinality=max_salt )
Complexity Memory: O(sizeof(blob)) CPU:
O(num_chunks) DB:
O(num_salted_partitions), where
num_salted_partitions = min(num_chunks, max_salt) Latency Maximum
batches concurrency divided by the num_salted_partitions times the
single batch latency. If all batches can be sent out in parallel,
the whole write is going to take the time it takes to write a
single salted partition data. Read On a read path, we are going to
start with reading total_chunks and
salt_cardinality from the “metadata row” of a specific
Key: row with (key=Key, salt=0, chunk_id=0) primary key. If we have
stored any data for the Key, this row should exist. Once we have
total_chunks and salt_cardinality values, we can
calculate primary key values for every chunk of the original blob
we stored before, and read them all in parallel. Below you can find
a pseudo-code implementing this idea. def read_key_blob(key:
bytes): # SELECT (total_chunks, salt_cardinality) FROM
keyspace1.standard1 # WHERE key=key AND salt=0 AND chunk_id=0
total_chunks, max_salt = get_num_chunks(key=key) if not
total_chunks: return None # No data for this key
salted_results_futures = [] for i in range(min(total_chunks,
max_salt)): # Full partition read salted_results_futures.append(
async_read(device_id=device_id, salt=i) ) # Poll for completions;
can also use async callbacks salted_partition_data = [] while
salted_results_futures: not_finished = [] for fut in
salted_results_futures: if fut.done():
salted_partition_data.append(fut.result()) else:
not_finished.append(fut) salted_results_futures = not_finished #
Reassemble blob in correct order chunks: List[bytes] = [None] *
total_chunks for partition_data in salted_partition_data: for row
in partition_data: chunks[row['chunk_id']] = row['chunk'] #
Zero-copy binary iterator over the original chunk return
itertools.chain.from_iterable(chunks) Complexity Memory:
O(sizeof(original blob)) CPU:
O(num_chunks) DB:
O(num_salted_partitions), where
num_salted_partitions = min(num_chunks, max_salt) Solving Different
Blobs’ Version Problem As with regular large partition salting,
there are some challenges: How to ensure the chunks you read belong
to the same version of the blob? How to ensure concurrent writers
of different blob versions to the same Key don’t leave the
database’s data in an inconsistent state? A rather common approach
to solving the first issue is to add a ‘version’ non-key column:
Writers must guarantee that every time they write a new version of
the blob, they assign the same cluster-unique version identifier to
every chunk (in order to ensure that all chunks of that specific
version share the same identifier). A reader would always verify
that the versions of each chunk (row) he/she reads for a specific
Key match. And if they don’t — one needs to retry a read. Solving
the second issue on the DB level is not recommended. It would
require using atomic transactions like CQL LWT, which would
introduce a performance overhead of their own. A better approach is
to ensure the atomicity of writes on the application level by
ensuring that there is always a single writer to the same
(original) Key at any given point in time. One way to implement
this is to have writer Agents manage specific Shard Key ranges.
Each Agent acts as a consumer for an MPSC queue and is responsible
for writing new versions of blobs belonging to its assigned keys.
In general, solving these problems is outside the scope of this
blog. Benefits Compared to Classic Salting One can choose any blob
chunk size (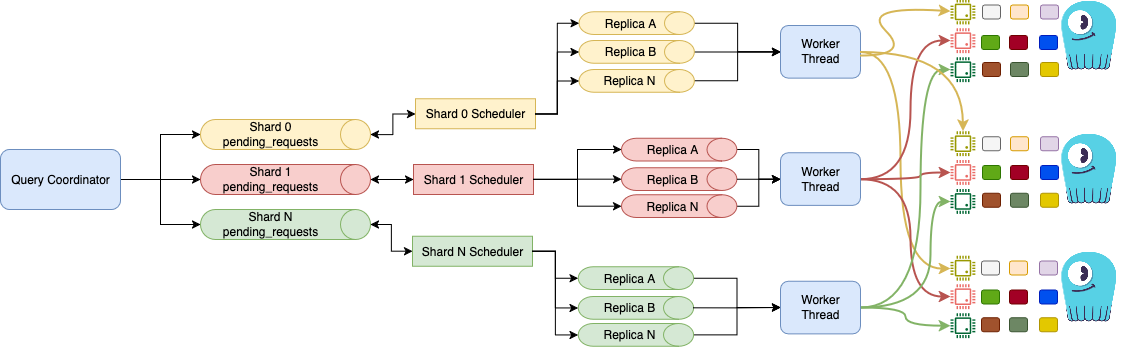{kind=link}
MAX_CHUNK_SIZE) and any salting
cardinality (MAX_SALT) for every key without impacting
other keys writes or reads. Unnecessary reads of empty partitions
in the read path are eliminated at the price of an additional small
read of 8 bytes. Examples of Approaches When Choosing
MAX_CHUNK_SIZE and MAX_SALT Approach How to configure Pros Cons
Fixed maximum chunk size Always use the same
MAX_CHUNK_SIZE for all blobs. Choose different
MAX_SALT values per key depending on the blob size to
control the size and the number of salted partitions. Use it if you
want to create a predictable load on the internal memory allocation
system. The number or the size of salted partitions may grow large
for big blobs. Fixed maximum number of salted partitions per
original key Always use the same MAX_SALT for each
key. You may choose to pick a different MAX_CHUNK_SIZE
to control the number of rows in each salted partition. Same CPU
complexity for read and write operations. Some partitions or cells
can get big for big blobs. Control the number of
single-row/single-shard partitions to be above a particular portion
of the total population Choose MAX_SALT to be 1 for
blobs below a certain size, e.g. P99 blob sizes in the data
population. Control the amount of data loss in case of losing a
quorum. If the threshold is chosen to be some big value, it may
create huge partitions, which will in turn create bottlenecks on
corresponding shards (CPUs). Clarifications About the Last Policy
One of the reasons that we want to salt large partitions (in this
particular case, we are effectively salting a “large partition that
has all the chunks of our original blob”) is to avoid creating a
bottleneck on a single shard. By salting, we are distributing its
data among many shards. That not only allows reading and writing
its smaller parts in parallel, but also distributes the
corresponding overhead among multiple shards of the ScyllaDB
database. However, this same distribution is going to become our
nemesis when we try to estimate the “blast radius” of data
consistency loss when we lose a quorum. Let’s do a quick
estimation. Assume the following configuration:
Cluster: 3 racks (A, B, and C), each rack having 2
nodes A1, A2, B1, B2, C1, C2 correspondingly.
Keyspace: NetworkTopologyStrategy with RF=3 in the
current DC. Write consistency: LOCAL_QUORUM (this
is a common consistency setting that, when paired with a
LOCAL_QUORUM read, ensures immediate visibility of all writes) When
we write with a LOCAL_QUORUM, we always write to all 3 replicas —
however, the write request is reported as a success when 2 out of 3
replicas acknowledge the write. Therefore, when we estimate
potential consistency loss, we should always assume the worst case
scenario of when every write has only reached 2
out of 3 replicas. Let’s now assume that nodes A1 and B1 are lost,
and so is all their data. If blobs are stored as-is (no chunking)
as a single key-value row/partition, then this would mean that we
lost a guaranteed consistency for about 25% of our data
set: A1 has data of ~50% of the population and there is a
~50% probability that keys replicated on A1 are also replicated on
B1. To reduce this number, one should provision more nodes
per-rack. Number of nodes per rack Possible data loss amount when
losing 1 node in each of 2 racks 3 ~11% 4 ~6.25% 5 ~4% … … If blobs
are chunked and salted — each with MAX_SALT of at
least as the number of nodes in a single rack — then statistically,
each node in the cluster is going to have some chunks of each blob.
For the above scenario, we would have to assume that we lost
consistency of every key: 100% data loss. Total
data consistency loss is a critical scenario that database
administrators strive to avoid. So, how can this risk be reduced?
One option is to use a hybrid salting strategy, as presented above.
If all your blobs are large or blob sizes are uniformly
distributed, then you may want to chunk them and store
each blob’s chunks as a single partition: always use
MAX_SALT=1. If your blob size distribution has
a high tail (e.g. P99 is 10MB while the average blob size
is 300 bytes), then add only 1% to the value in the table above. To
do this, you can use MAX_SALT=1 for all blobs below
10MB and use a larger MAX_SALT (e.g. 100) for all
blobs that are larger or equal than 10MB. It allows for effective
management of the data loss blast radius. It enables the
distribution of the largest blobs across multiple shards,
fulfilling the primary goal of chunking. Demo Here is a small
demonstration of the idea described above. We wanted to show that
the latencies of reading and writing of the chunked 60MB blobs is
comparable to latencies of 1MB or 64KB small blobs. The small chunk
writes and reads steps were running with the fixed concurrency of
15 to make sure we are not hitting any possible bottlenecks. We
have implemented a write API that receives blob and salting
parameters and stores it in a chunked form as described above. We
have also implemented a corresponding read API that reads the blob
previously stored by a write API back and returns it as a vector of
chunks. We are going to measure the latency of API calls above: For
writes: the time all chunks of a given blob are written to the DB.
For reads: the time all chunks are read from the DB and the
corresponding vector of chunks is returned to a caller. We are
going to issue APIs that chunk the blob with concurrency 1 in order
to avoid the possibility of queuing and get the clean latency
measurements. You can find the API for managing salted blobs within
the SaltedBlobStore class in
this repository, with implementations available in both Python
and C++. The following results were obtained using the C++ API. The
benchmark tool has 4 steps: Write a given number of blobs
of a given size with one of the write APIs mentioned above. Read
the blobs written in step 1 using one of the read APIs mentioned
above. Write the same amount of data written in step 1 using single
chunk writes of the same size we used for chunking blobs in step 1.
Read the data written in step 3 back. Our setup is: ScyllaDB: a
single node with 15 shards: i8g.4xlarge AWS VM. Loader: a single
c5.12xlarge AWS VM. Compactions are disabled to make steps 1 and 3,
and 2 and 4 comparable since they run back-to-back. We write 1000
blobs 60MB each in the demo. In the first iteration, we use 1MB
chunks and max_salt=60 since there will be exactly 60
chunks. In the second iteration, we use 64KB chunks and
max_salt=100. Then we compare the API-level latencies
between these two iterations. Benchmark Results Iteration 1 Total
amount of data written/read: Large blobs : 1,000 × 60 MiB =
58.59 GiB total Small blobs : 60,000 × 1024 KiB ≈ 58.59 GiB total
Chunk size : 1 MB max_salt=60 small blobs concurrency=15 large
blobs batch write/partitions read concurrency = 60 (all partitions
are read and written in parallel) Metric Large Write (60MB)
Large Read (60MB) Small Write (1MB) Small Read (1MB) Effective
Throughput 682.1 MiB/s 758.3 MiB/s 1420.1 MiB/s 1238.1 MiB/s
Execution Duration 1m 28s 1m 19s 42.3 s 48.5 s Operation Count
1,000 1,000 60,000 60,000 Latency Metric Large Write (60MB) Large
Read (60MB) Small Write (1MB) Small Read (1MB) Minimum Latency 85.7
ms 64.0 ms 2.5 ms 1.2 ms Median (p50) 87.7 ms 74.9 ms 7.3 ms 10.5
ms Tail Latency (p99) 92.5 ms 87.1 ms 38.6 ms 39.4 ms Maximum
Latency 98.1 ms 91.2 ms 59.7 ms 80.0 ms Iteration 2 Total amount of
data written/read: Large blobs : 1,000 × 60 MiB = 58.59 GiB
total Small blobs : 960,000 × 64 KiB ≈ 58.59 GiB total Chunk size :
64 KB max_salt=100 small blobs concurrency=15 large blobs batch
write/partitions read concurrency = 100 (all partitions are read
and written in parallel) Metric Large Write (60MB) Large
Read (60MB) Small Write (64KB) Small Read (64KB) Effective
Throughput 998.0 MiB/s 1022.9 MiB/s 1124.5 MiB/s 438.8 MiB/s
Execution Duration 1m 0s 58.7 s 53.4 s 2m 17s Operation Count 1,000
1,000 960,000 960,000 Per-Operation Latency
Characteristics Latency Metric Large Write (60MB) Large
Read (60MB) Small Write (64KB) Small Read (64KB) Minimum Latency
58.8 ms 52.3 ms 0.6 ms 0.6 ms Median (p50) 59.8 ms 57.8 ms 0.8 ms
0.9 ms Tail Latency (p99) 64.2 ms 69.6 ms 1.1 ms 1.2 ms Maximum
Latency 91.9 ms 76.0 ms 2.0 ms 23.8 ms These results validate the
efficiency of the salting strategy for massive objects. While we
were writing with virtually the same throughput as cassandra-stress
at the beginning of the article, using 64KB chunking results in
about 10s faster average writes for the same 60MB of data and 22x
lower P99 write latencies. We see that 1MB chunking results in
about 40% worse latency across all percentiles compared to 64KB
chunking. This is not very surprising because 1MB chunks are pretty
large blobs themselves and trigger the same issues like larger
blobs. Overall, these performance metrics are highly favorable
compared to the raw 60MB blobs’ write/read latencies we saw with
cassandra-stress in the original test we shared. Conclusion: High
Performance, Controlled Risk The challenge of storing large blobs
in ScyllaDB is fundamentally about managing memory pressure and
latency. Our experiments confirmed that a large 60MB blob written
as a single key-value row resulted in a write latency of about
567ms/1436ms average/P99 latency. The Modified Salting Technique
solves this bottleneck by transparently fragmenting the large blob
and allowing its parts to be processed in parallel across multiple
shards. This approach successfully reduces write/read latency to
highly performant levels, comparable to small key-value operations
(60ms/64ms average/P99) with a very low tail latency. Plus, there
is a good potential to improve this even further if one increases
the write/read concurrency. This technique offers flexibility not
found in classic salting: most notably, the ability to configure
the salting cardinality (MAX_SALT) on a per-key basis.
This flexibility is the key to managing a delicate trade-off: For
optimal performance and shard distribution, a large
MAX_SALT is preferred. For critical data where
minimizing the data loss blast radius during a
quorum failure is paramount, a low MAX_SALT (e.g.,
MAX_SALT=1) can be used to isolate the data to fewer
nodes. By implementing a hybrid approach — using low salting for
small to medium blobs, and high salting for the largest ones —
administrators can achieve high throughput and low latency for
their entire data set while retaining control over data loss risk.
This modified salting technique can help users squeeze better
performance from ScyllaDB when dealing with mixed-size datasets and
large object storage. If you’re interested and want to give this
chunked blob technique a try, you can find working code samples and
the benchmark used above at
https://github.com/scylladb/scylla-code-samples/tree/master/chunking-large-cells/. Riding the Raft to Strong Consistency in ScyllaDB
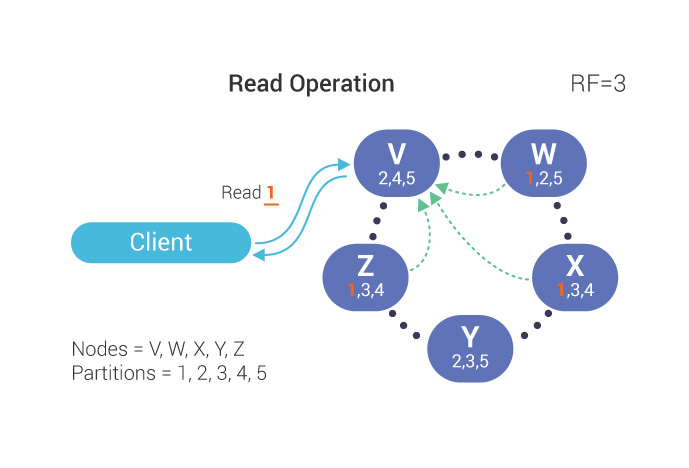
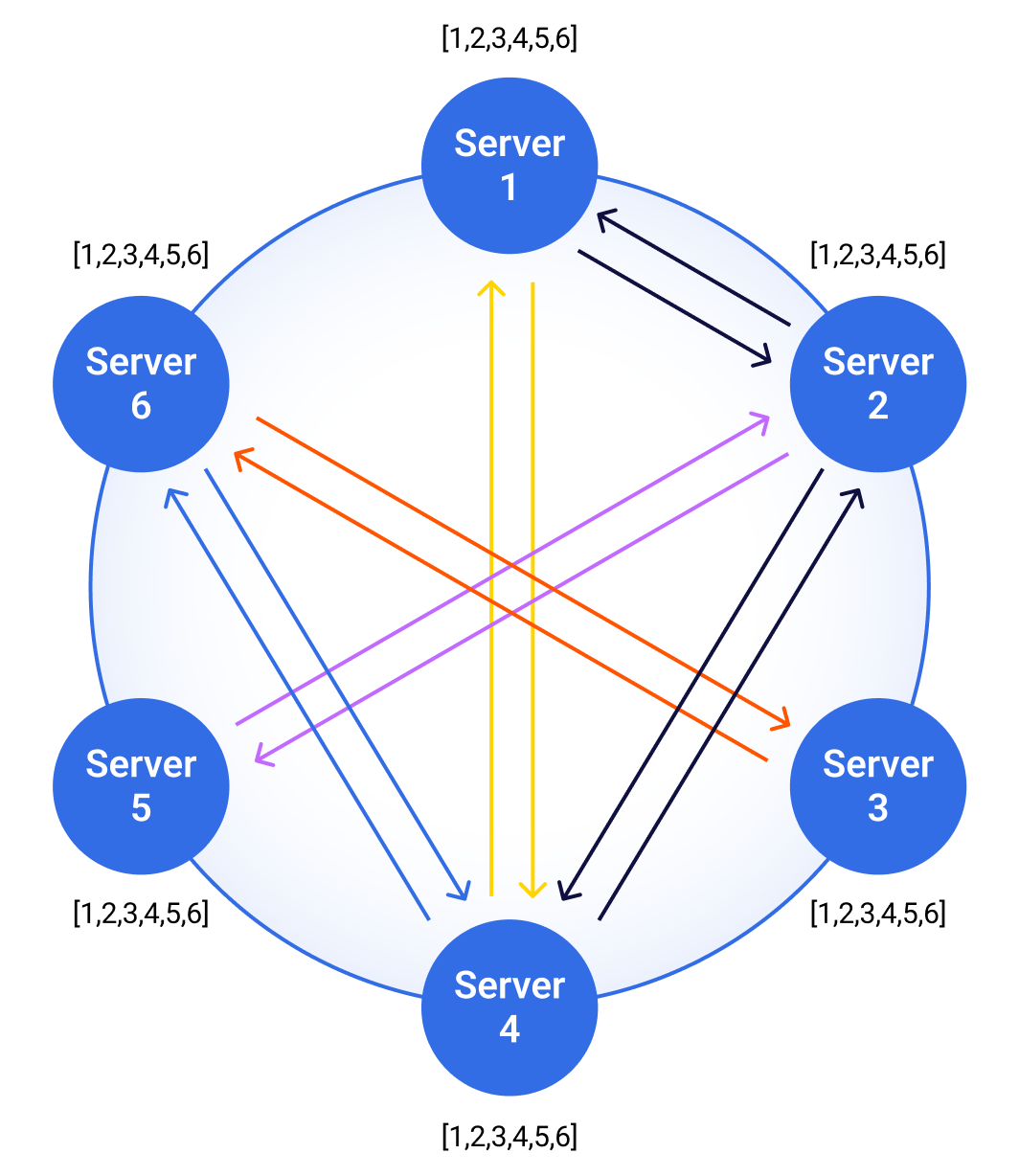
How ScyllaDB is using per-tablet Raft groups to bring strong consistency to data, without sacrificing the parallelism that makes it fast Distributed systems do not give us simple guarantees for free Distributed databases live in a world where failure is normal. Nodes fail. Networks could have partitions. Clocks might be different in each area that you’re working in. Messages can be delayed or never arrive because of the network itself. A request that looks simple from the application side may cross replicas, shards, data centers, coordinators, and recovery paths before the database can safely answer it. Consistency is one of the most important contracts between the database and the application…and it’s hard. When the database says a write succeeded, what exactly does that mean? When a second client reads the same key, what state should it see? When two updates race, who wins, and can the application reason about the result? For many workloads, eventual consistency is the right approach. It gives a distributed database room to stay highly available and fast, even when part of the system is under stress. For now, these workloads are where ScyllaDB shines. But for other workloads, “eventually correct” creates too much ambiguity. Those workloads need a stronger contract. Eventual consistency was the right foundation for ScyllaDB ScyllaDB started as a high-performance, Cassandra-compatible, eventually consistent database. That model is powerful: the system is leaderless, work is distributed across shards, and applications choose consistency levels such as ONE, QUORUM, or ALL (depending on their needs). In this model, a client sends a write to a coordinator, the coordinator forwards it to replicas, and the operation is acknowledged according to the selected consistency level. Reads follow a similar pattern: replicas respond, and the coordinator waits for enough responses to satisfy the requested consistency level. Figure 1: Write and read patterns This design gives applications a flexible tradeoff between latency, availability, and consistency. It remains valuable, especially for high-scale workloads that prioritize availability and throughput. But some parts of a database should not be “eventual” Eventual consistency becomes harder when the data being changed is not naturally commutative, when different observers must agree on one order of events, or when a wrong answer is expensive. Metadata is the clearest example. Schema, topology, tablet placement, and cluster state describe the database’s internal operations. If nodes disagree about this information, the system becomes harder to operate safely. The same pattern appears in application data. Counters, account balances, inventory reservations, entitlement checks, idempotency records, and conditional updates all become simpler when the database can provide a clear, strongly ordered answer. Without that guarantee, application developers often compensate by adding retries, custom conflict resolution, reconciliation jobs, or application-side locks. Figure 2: Gossip-based topology spreads membership information without a single global source of truth, which is powerful for availability but eventually consistent by design. For example, “last-write-wins” sounds simple: keep the newest update. But if two clients update the same value at the same time, one update can disappear.{kind=link}
{kind=link}
{kind=link}
Initial value: {} Client
1 writes: {A} Client 2 writes: {B} Final value: {B} Both
writes may have been accepted, but only one survives. The problem
is that last-write-wins avoids coordination, but it does not merge
intent. For mutable data, this can mean lost updates. To learn
more: https://aphyr.com/posts/294-jepsen-cassandra
Strong consistency gives the system one accepted order An
alternative approach is strong consistency. Instead of allowing
independent updates to happen concurrently and converge later, the
system establishes one accepted order for operations. In practical
terms, this means that once an operation is committed, later
operations observe that committed state according to the
consistency model. This provides correctness as well as simplicity.
Developers can reason about the database as if there is one clear
sequence of operations. Operators can reason about topology and
schema changes as deterministic state transitions. And the database
can remove entire classes of ambiguity because it no longer needs
to guess which version of the world is the right one. Strong
consistency is an all-around simpler programming model for the
parts of the application where correctness, ordering, and
predictability matter more than the lowest possible write latency.
Why Raft is the right building block Raft provides the foundation
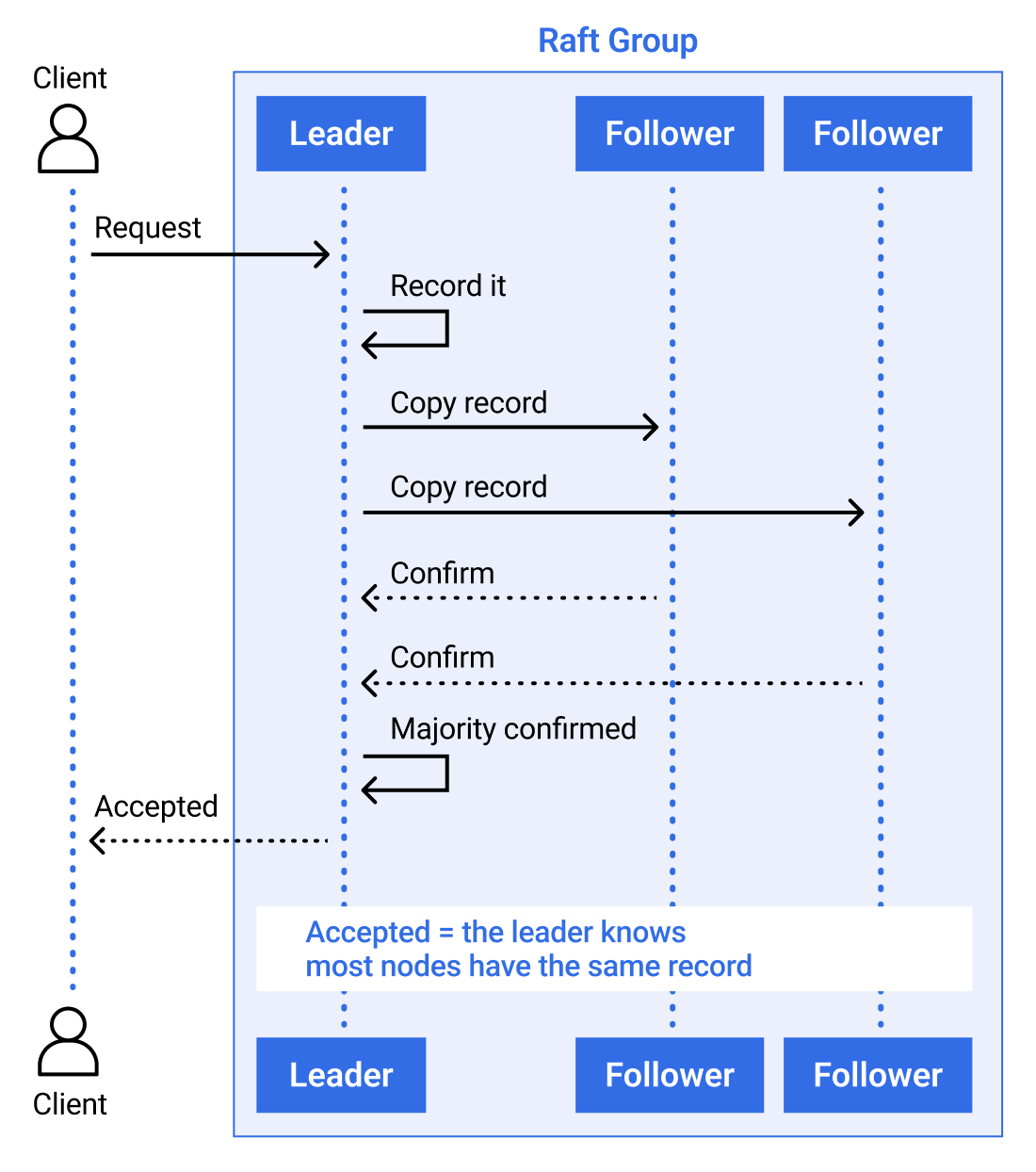
for this stronger consistency model. At a high level, a Raft group
chooses one node to be the leader. The leader receives the request,
records it, and makes sure most of the group has the same record.
Only then does the group treat the request as accepted.
Figure 3: Raft request access by majority process Because
all nodes follow the same ordered list of accepted requests, they
all reach the same result in a clear and predictable way. This
model is especially useful in a distributed database because it
gives the system a clear answer to a hard question: Who is
allowed to decide what happens next? In Raft, the leader
proposes the order and the majority confirms it. ScyllaDB adopted
Raft because some database operations are too important to be left
to eventually converging metadata. Schema changes, topology
changes, and strongly consistent data operations all need a clear,
agreed-upon order. Without that, two nodes may observe changes in
different orders, or the system may need complex recovery logic to
repair disagreement after the fact.
Figure 4: Raft turns a distributed decision into an ordered
log: leader election, append, replicate to a majority, commit, and
apply. This is also important for elasticity. ScyllaDB’s
tablet architecture is designed for flexible data distribution
across the cluster, and Raft-managed topology allows operations
such as adding nodes and moving data to be coordinated safely.
ScyllaDB uses tablets, together with consistent topology updates,
as a foundation for faster and more flexible scaling. In other
words, ScyllaDB adopted Raft not just because Raft is a well-known
consensus algorithm, but because it gives the database a reliable
coordination layer. It replaces “every node eventually figures it
out” with “the group agrees on the order first, then applies the
result.” That is the foundation needed for strong consistency;
there’s just one: Agreed order. Committed history. Deterministic
path from request to replicated state. At ScyllaDB, the first step
in adopting Raft was to use it for topology and metadata changes.
This gave those critical operations strong consistency guarantees
while also reducing complexity across the system.
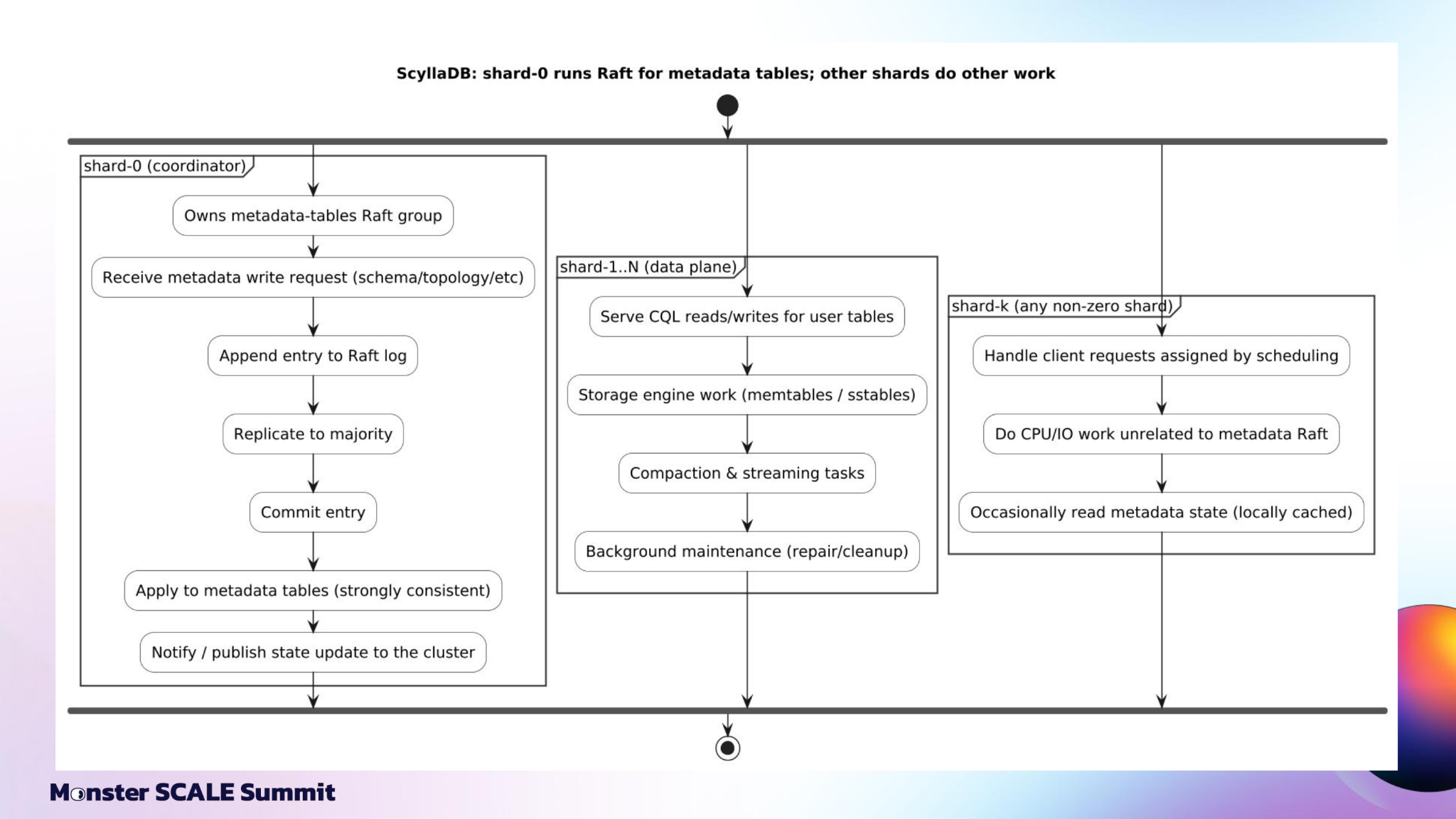
Figure 5: In ScyllaDB, shard 0 runs Raft for metadata tables
while the other shards continue doing user-data and storage-engine
work. The next milestone for ScyllaDB: strongly consistent
tables Our next step is bringing the same idea to user data through
strongly consistent tables. A strongly consistent table is built on
top of the Raft log. A write is routed to the Raft leader for the
relevant tablet group, appended to that group’s log, replicated to
a majority, committed, and applied to the storage engine.
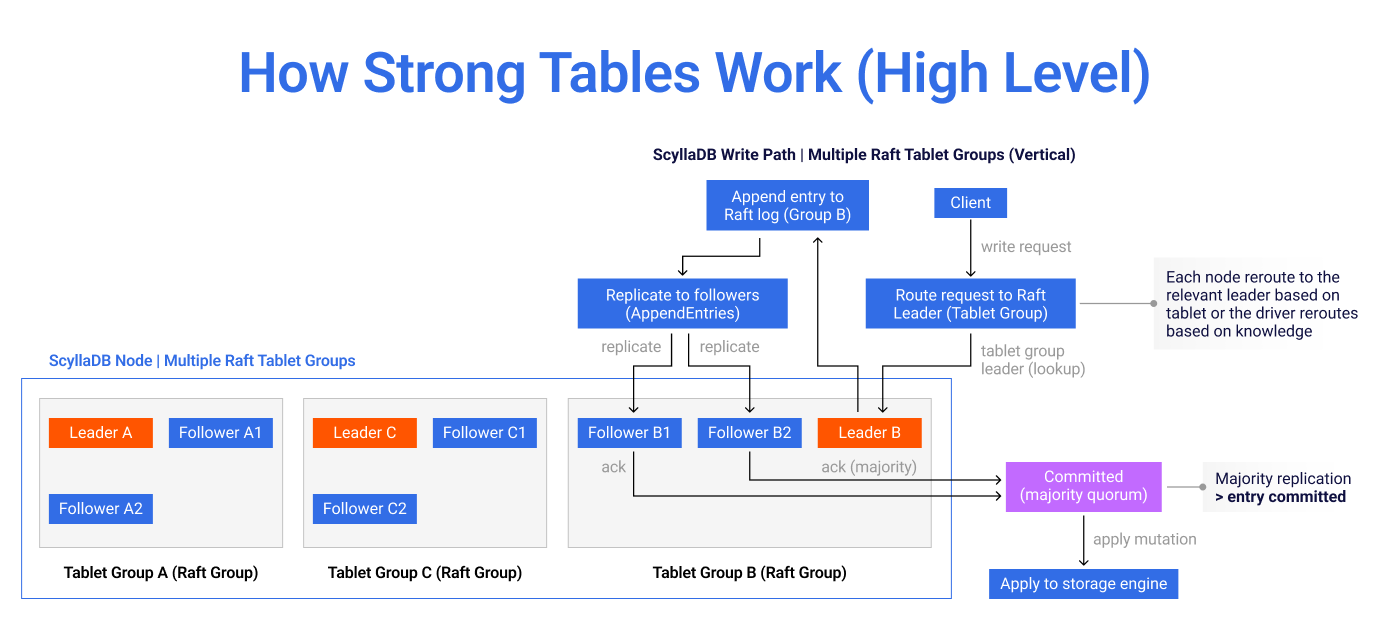
Figure 6: High-level strongly consistent write path: route to
the tablet group leader, append to the Raft log, replicate to a
majority, commit, and apply to storage. This is a major shift
in how users can model correctness in ScyllaDB. Instead of treating
strong guarantees as a special case workaround, users can choose a
consistency model at the data-modeling level. Tables that need the
classic high throughput eventual consistency behavior can keep it.
Tables that need stronger ordering can use the strong path. It’s
important to note: ScyllaDB is not replacing eventual consistency.
We are offering multi-consistency. Our users will be able to choose
the right consistency model for each workload. And we will deliver
strong performance in both cases. Why a Raft Group for each tablet?
In ScyllaDB, we already use Raft for important system-level
coordination. For example, Raft is used to safely sequence topology
and schema metadata changes. That makes cluster operations
consistent and reliable. So a natural question is: If we
already have Group 0, why not use it as the single synchronization
point for all strongly consistent data operations? At
first glance, that sounds simpler. We already have one Raft group
in the system. We could use it as the “master sync point” for every
read, write, and data-related operation. But, unfortunately, it’s
not that simple. ScyllaDB clusters can contain many tablets.
Tablets are the basic units of data distribution: each tablet owns
a portion of a table’s data and can be independently managed and
moved across the cluster. To understand the issue, imagine a busy
system with many tablets, heavy reads, heavy writes, topology
activity, background work, maintenance operations, and user traffic
all happening at the same time. If all of these operations had to
pass through a single Raft group, that group would become a global
synchronization bottleneck. Because Raft is a consensus protocol,
operations must be ordered and committed consistently. (That’s what
gives us correctness). But if one global group is responsible for
ordering everything, then unrelated operations are forced into the
same queue. A write to one tablet may have to wait behind work for
another tablet. A read or write on one part of the dataset may be
delayed by background activity somewhere else in the cluster. All
this hurts both latency and throughput. A better option is to
“divide and conquer.” Since the tablet is already the natural unit
of data ownership, we can also make it the natural unit of
synchronization. Instead of forcing all strongly consistent
operations through one global Raft group, each tablet gets its own
Raft group. This means each tablet handles its own coordination,
replication, and bookkeeping. Operations on one tablet do not need
to block unrelated operations on another tablet. The system can
make progress in parallel, across many independent Raft groups,
instead of serializing everything through a single global queue.
The result is a much more scalable architecture with: Lower
contention: Each Raft group handles only the operations
for its own tablet. Better parallelism: Many
tablets can process strongly consistent operations at the same
time. Improved throughput: The system is no longer
limited by one global synchronization point. Lower
latency: Unrelated operations do not wait behind each
other as often. Better user experience: Strong
consistency becomes practical without turning the entire database
into a single serialized pipeline. This is the same basic reason
ScyllaDB’s tablet architecture exists in the first place: splitting
data into smaller independent units allows the system to scale,
rebalance, and operate in parallel. Tablets were designed to
support faster, more flexible scaling by separating data ownership
from fixed server ownership. A single global Raft group is nice
because it is easier to reason about. However, ScyllaDB is built
for high-throughput, low-latency workloads. A single global queue
for all of them would immediately become the bottleneck. By
assigning a Raft group to each tablet, we keep the correctness
properties of Raft while preserving the parallelism that makes
ScyllaDB fast. Each tablet becomes an independent unit of
consistency. The cluster as a whole can continue to behave like a
distributed, parallel database rather than a single synchronized
queue. In short: Group 0 is great for global
metadata. Per-tablet Raft groups are what make
strong consistency scalable for user data. Raft
leaders and followers: one voice for the group Raft is a consensus
protocol designed around a simple idea: instead of allowing every
replica to independently decide what should happen next, the group
elects one replica to act as the leader. The other
replicas become followers. This leader-based model
makes the system easier to reason about because all changes flow
through a single authority for that Raft group. The original Raft paper describes
this as one of Raft’s main design choices: decomposing consensus
into understandable pieces, especially leader election and log
replication. In normal operation, the leader is
responsible for accepting new operations, appending them to its
log, and replicating those log entries to the followers. A follower
does not independently decide the order of operations. Instead, it
follows the leader’s log and acknowledges replicated entries. Once
an entry is safely replicated to a majority of the group, it can be
considered committed and applied to the replicated state machine.
This is the core mechanism that allows multiple machines to behave
as if they agreed on one ordered history of changes. The important
point is that the leader is not “more correct” than the followers.
It is simply the replica currently elected to coordinate the group.
Followers still store the replicated state, validate the leader’s
messages according to the Raft rules, and participate in making
progress by acknowledging replicated entries. The leader can only
commit entries when it has agreement from a quorum. This is why
Raft depends on a majority of replicas being available; without a
quorum, the group cannot safely make new decisions. ScyllaDB’s
Raft documentation also highlights this quorum requirement for
Raft-managed operations. A useful way to think about it is this:
The leader proposes the order. The followers confirm and
persist that order. The majority makes it durable. Raft
leaders also send periodic heartbeat messages to followers. These
heartbeats tell the followers that the leader is still alive and
still responsible for the current term. As long as followers keep
receiving valid communication from the leader, they remain
followers. If a follower stops hearing from the leader for long
enough, it assumes the leader may have failed and starts an
election by becoming a candidate. If that candidate receives votes
from a majority, it becomes the new leader. This election mechanism
allows the group to recover automatically when the current leader
crashes or becomes unreachable. This distinction between leader and
follower is especially important in distributed databases. A
database cluster is not running on one machine. It is running
across many machines, and those machines can fail, restart,
disconnect, or see events in different orders. Without a clear
coordination model, two replicas could make conflicting decisions
at the same time. Raft avoids that by ensuring that, for a given
term and Raft group, there is one leader responsible for sequencing
new changes. In ScyllaDB, Raft has already been used to make
important metadata operations safer and more consistent, including
schema and topology changes. ScyllaDB’s work on Raft-managed
topology means topology operations are internally sequenced
consistently, rather than relying on each node to independently
converge on the same result. ScyllaDB also has one place that
coordinates topology changes together with the Raft leader. If that
leader goes down, another leader can take over and continue from
the same shared information, instead of guessing or starting from a
different view. For strongly consistent data, the same basic idea
applies: the leader of the relevant Raft group is the place where
the ordered history of that group is created. A write is not just
“sent somewhere and eventually copied.” It is placed into a
replicated log, agreed on by a majority, and then applied in the
same order by the replicas. Followers are not passive backups in
the weak sense; they are active participants in preserving the
agreed history. This model gives us a clean mental picture:
Without Raft: replicas may need to reconcile
different views after the fact. With Raft:
replicas agree on the order first, then apply the result. That is
the key difference. Raft does not remove the complexity of
distributed systems; failures, latency, partitions, and recovery
still exist. But it gives the system a disciplined way to handle
that complexity. The leader gives each Raft group a single
coordination point, the followers provide durable replicated state,
and the quorum rule ensures that progress is made only when enough
replicas agree. In other words, Raft leader/follower replication is
not about creating one “special” node forever. It is about creating
a temporary, elected coordinator that gives the group one
consistent voice. If that voice disappears, the group elects
another one. The result is a system that can keep a strongly
ordered history of changes even while individual machines come and
go. Leader awareness: sending requests to the right place Now that
we’ve seen how every Raft group has a leader, let’s look at the
next important question: How does the client know where to
send the request? In a Raft-based system, the leader is
the replica that coordinates the work for the group. It decides the
order of operations, appends new entries to the replicated log, and
drives replication to the followers. For ScyllaDB Strong
Consistency, where every tablet has its own Raft group, this means
that every tablet also has a current Raft leader. That creates an
important difference from eventual consistency. With eventual
consistency, a client request can usually be sent to one of the
replicas, and that replica can act as the coordinator for the
operation. The driver does not necessarily need to know which
replica is “special,” because there is no Raft leader that must
order the operation first. With strong consistency, the situation
is different. If a request reaches a follower, that follower cannot
independently decide the order of the operation. The leader must
coordinate the operation. The follower may have the data, and it
may be part of the Raft group, but it is not the replica currently
responsible for sequencing new writes or strongly consistent
operations. So the request has to reach the leader. Request
forwarding To make this work, ScyllaDB implements request
forwarding. It works like this: The client sends a request
to one of the replicas. If that replica is the Raft leader for the
tablet, it handles the request directly. If that replica is a
follower, it acts as a proxy for the request. The leader processes
the request through Raft. The result is returned back through the
forwarding replica to the client. This gives us an important
correctness property: Even if the client reaches the wrong
replica, the operation is still coordinated by the Raft
leader. That is exactly what we want. The leader remains
the single place where the ordered history of the tablet is
created. Followers can help route the request, but they do not
bypass the leader or make independent decisions. This forwarding
mechanism is especially useful because leadership can change. A
leader may fail, restart, become unreachable, or step down. When
that happens, the Raft group elects a new leader. Request
forwarding gives the system a way to continue operating even when
the client does not yet know about the new leadership state. The
cost of forwarding However, request forwarding has a cost. If the
client sends the request to a follower, the request has to make an
extra network hop: client → follower → leader → follower →
client Instead of the simpler path: client → leader →
client That extra communication adds latency. It also
increases the number of messages inside the cluster. For occasional
requests, this may be acceptable. But for a high-performance
database, especially under heavy read and write workloads,
unnecessary network hops matter. This is where leader awareness
becomes important.
Leader-aware drivers A leader-aware driver allows
the client driver itself to learn which replica is the leader for a
given tablet. Instead of blindly sending requests to any replica
and relying on forwarding, the driver can send future requests
directly to the leader. The first request may still go to any
replica. If it reaches a follower, the follower can forward it to
the leader. But when the response comes back, the driver can also
learn: “For this tablet, this replica is currently the
leader.” From that point on, the driver can route requests
directly to the leader. So the flow becomes: The driver sends an
initial request. If needed, ScyllaDB forwards the request to the
current leader. The response includes updated leader information.
The driver remembers the leader for that tablet. Future requests go
directly to the leader. This keeps the correctness benefit of
forwarding, while reducing its performance cost. Forwarding is
still needed Leader-aware drivers do not remove the need for
request forwarding completely. Leadership is not permanent. A Raft
leader can change at any time due to failures, restarts, topology
changes, or elections. When that happens, the driver may
temporarily have stale information. In that case, forwarding is
still the safety net: If the driver sends a request to the
old leader or to a follower, ScyllaDB can forward the request to
the new leader and update the driver again. So forwarding
remains important, but it becomes the exception rather than the
normal path. Instead of paying the forwarding cost on every
request, we mainly pay it at the beginning of
communication, after the leader has changed, or when the driver’s
leader information is stale. That is a much better model
for performance. Balancing correctness and performance Leader
awareness gives us the best of both worlds. Request forwarding
gives us correctness and simplicity: requests always reach the Raft
leader, even if the client does not know who the leader is.
Leader-aware drivers give us performance: once the driver learns
the leader, it can avoid unnecessary hops and send requests
directly to the right replica. For strongly consistent workloads,
this is a major optimization. Strong consistency already requires
coordination, replication, and quorum agreement. We do not want to
add avoidable network hops on top of that. By making the driver
aware of tablet leadership, ScyllaDB can preserve the Raft
correctness model while reducing latency and improving throughput.
In short: Request forwarding makes strong consistency
work. Leader-aware drivers make it fast.
The leader-aware driver is planned for the 2026.3
release. In 2026.2 we release forwarding. The
strongly consistent read path: reading from the leader and using a
barrier After understanding that every Raft group has a leader, and
that writes must be coordinated by that leader, the next natural
question is: What about reads? At first glance,
reads may look simpler than writes. A read does not change the
data, so it may seem safe to read from any replica. But with strong
consistency, this is not always enough. The problem is that
replicas may not all be at exactly the same point in the Raft log
at the same time. A follower can be slightly behind the leader. It
may still be catching up on committed entries. If we read from that
follower without any additional coordination, we may accidentally
read an older version of the data. For eventual consistency, this
may be acceptable depending on the chosen consistency level and
workload. For strong consistency, we need a stronger guarantee:
A read must observe the latest state that was safely
committed before the read. That means the read path also
needs to respect the Raft ordering model. Reading from the leader
The simplest way to make a strongly consistent read is to send the
read to the Raft leader. The leader is the replica that coordinates
the Raft group. It receives operations, orders them, replicates
them, and knows the current progress of the group. Because the
leader is the place where the group’s ordered history is created,
reading through the leader gives us a natural consistency point.
The basic read path looks like this: The client sends a read
request. The request is routed to the Raft leader for the tablet.
The leader makes sure it is still allowed to act as leader. The
leader reads from the state that reflects the committed Raft log.
The result is returned to the client. This keeps the read aligned
with the same ordering model used by writes. In other words:
Writes go through the leader to enter the log.
Reads go through the leader to observe the committed result
of that log. This gives the system a clean and
understandable consistency model. The leader is not only the place
where changes are ordered; it is also the safest place to observe
the latest committed state. Why reading from a follower is not
always enough A follower is still a valid replica. It participates
in the Raft group, stores the replicated log, and applies committed
entries. But a follower can temporarily lag behind the leader. For
example: A write is committed by the leader and a majority of
replicas. One follower has not applied for that committed entry
yet. A client reads from that follower. The client may see the old
value. From the point of view of that follower, nothing “wrong”
happened. It simply has not caught up yet. But from the point of
view of strong consistency, the reading may be stale. This is why
strongly consistent reads cannot blindly read from any replica
without additional coordination. If we want reads to be strongly
consistent, the system must prove that the replica serving the read
is up to date enough for that read. What is implemented today
Today, before serving a strongly consistent read, ScyllaDB runs
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
read_barrier(). This currently requires network
communication with a quorum and also waits for the Raft state
machine on the leader to apply any previously written commitlog
entries to memtables. In other words, the read must first make sure
the leader has caught up with all committed changes before
returning a result. In the near future, we plan to implement
Raft leases, which will allow the leader to serve
reads locally without additional network hops. Because of this, we
expect strong consistency performance to eventually be on par with
eventual consistency, and in some read-heavy cases, it may even be
better. How the leader keeps followers updated The Raft leader is
also responsible for keeping the followers up to date. When a new
operation is accepted by the leader, the leader appends it to its
local Raft log and then sends it to the followers. The followers
append the same entry to their own logs and acknowledge it back to
the leader. Once the leader receives acknowledgments from a
majority of replicas, the entry is considered committed. After
that, the committed entry can be applied to the actual database
state. The flow looks like this: Client request ↓
Raft leader appends entry to its log ↓ Leader
sends the entry to followers ↓ Followers append
the entry and acknowledge ↓ Majority
confirms ↓ Entry is committed ↓
Replicas apply the committed change The leader has two
jobs: It orders new operations. It
continuously brings followers to the same ordered state.
This is important for reads as well. A follower may temporarily be
behind the leader, even if it is healthy. That is why strongly
consistent reads usually go through the leader, or require an
additional synchronization step such as a barrier before the system
can safely answer from a known up-to-date state. How this impacts
application developers Strongly consistent tables simplify
application logic. Most developers building a payment flow, quota
system, inventory reservation, account state machine, or
idempotency layer don’t want to reason about replica divergence.
They just want the database to protect the invariant. Strong
consistency also improves predictability. Predictability is not
only about latency. It is about knowing what the system will do
when two clients race, when a node restarts, or when an operation
is retried. A deterministic ordering layer makes these cases easier
to explain, test, and debug. Users should also find that strong
consistency makes LWT and transaction workflows much better,
cleaner, and faster.
Figure 7: Application-level benefits: fewer eventual
consistency anomalies, better counters, better predictability,
simpler logic, and a path to better LWT behavior. How to use
strongly consistent tables This feature is still experimental so
please use it with caution.
Strong consistency is selected at the keyspace level. With the
{kind=link}
{kind=link}
strongly-consistent-tables experimental feature
enabled, create a tablets-based keyspace with consistency =
'global'. Tables created in that keyspace use the strongly
consistent path automatically, so applications continue to use
ordinary CQL reads and writes. There is no separate per-statement
switch for “strong consistency” in the query itself. CREATE
KEYSPACE sc_demo WITH replication = {'class':
'NetworkTopologyStrategy', 'replication_factor': 3} AND tablets =
{'enabled': true} AND consistency = 'global'; CREATE TABLE
sc_demo.orders ( id int PRIMARY KEY, status text, amount int );
INSERT INTO sc_demo.orders (id, status, amount) VALUES (1, 'paid',
100); SELECT * FROM sc_demo.orders WHERE id = 1; This keeps
the usage model simple: choose strong consistency when creating the
keyspace, then use ordinary CQL on the tables inside it. A
fundamental difference from eventual consistency is that strongly
consistent writes do not support user-provided timestamps, so
applications must let ScyllaDB assign them automatically.
More
about LWT Lightweight transactions are one of the places where
users already ask the database for stronger semantics. In
eventually consistent architectures, LWT is commonly implemented
through Paxos, which requires multiple phases such as prepare,
accept, and commit. That can add latency and complexity. A
Raft-backed architecture gives ScyllaDB a path toward a more
unified model: LWT-style behavior on top of a shared replicated
log. This should give you fewer duplicated mechanisms, fewer voting
rounds, and a simpler execution path. The long-term direction is
not “add another special protocol,” but “converge on one ordering
and replication layer where it makes sense.”
Figure 8: LWT can move from a separate Paxos-based path toward
a Raft-backed path with fewer voting rounds and a shared
replication layer. Performance Strong consistency is not free.
A Raft-based write requires a majority, and write latency can
increase compared with the fastest eventually consistent path. That
is the nature of asking the system to commit to one order before
acknowledging the operation. But the right comparison is not only
per-write latency. Strong consistency can also remove repair
overhead, conflict-resolution ambiguity, reconciliation logic, and
application-side complexity. For correctness-sensitive workloads,
paying a predictable coordination cost inside the database can be
far better than paying an unpredictable correctness cost across the
entire application stack.
Figure 9: Architecture convergence: Raft becomes the unified
ordering layer for topology, strongly consistent tables, and
LWT. We don’t expect our users to make every table strongly
consistent; this won’t be the default. Our goal is to give you a
choice so you don’t have to choose between a high-performance
database and a stronger correctness model. What’s available now and
what’s next The backbone implementation for strongly consistent
tables is in ScyllaDB 2026.2. Users can create a keyspace
configured for strong consistency, create strongly consistent
tables, and read and write to them. This is the foundation: the
core path proving that ScyllaDB can execute user-data operations
through a Raft-backed strong-consistency model. But there’s still
more to do. We’re still working on details like tablet migration,
tablet split and merge support, recovery behavior, and leader-aware
driver support. We’re expecting to release these features in
2026.3. That makes 2026.2 an important milestone: not the end of
the journey, but the point where the architecture becomes visible
and usable. ScyllaDB is evolving from a high-performance eventually
consistent database into a high-performance multi-consistency
distributed database.
Conclusion: strong consistency is about removing ambiguity
Distributed systems are already hard enough. The database should
remove ambiguity where ambiguity is dangerous. With Raft-backed
strong consistency, ScyllaDB gives users a clearer model for
workloads that need correctness, ordering, and predictability.
Eventual consistency remains the right choice for many high-scale
workloads. Strong consistency becomes the right choice when the
application needs one answer, one order, and one source of truth.
We’re excited to share this with you and look forward to your
feedback! {kind=link}
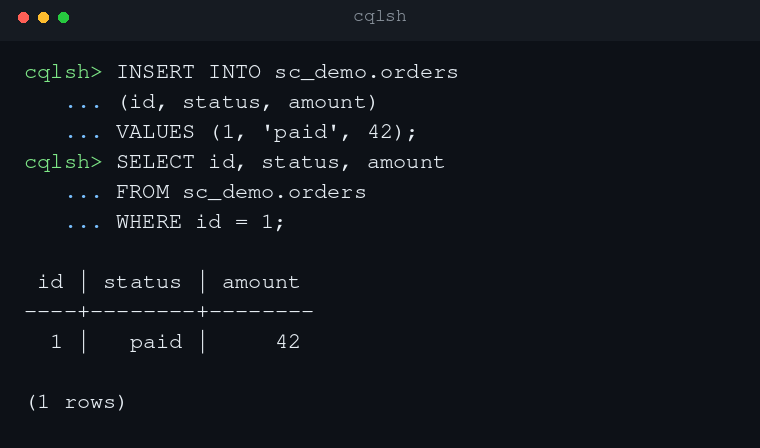{kind=link}
{kind=link}
{kind=link}
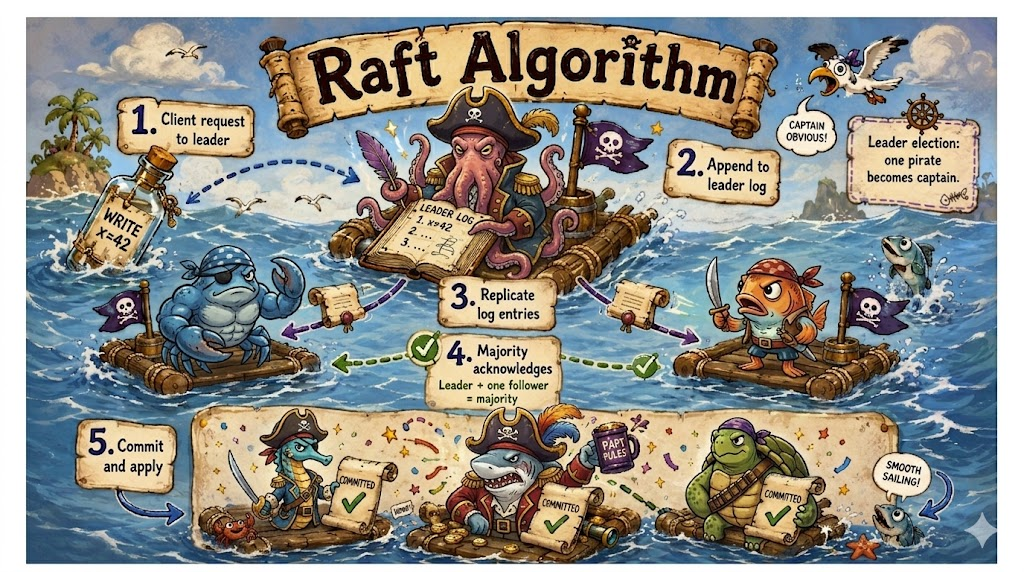{kind=link}
{kind=link}
The Evolution of Cassandra Data Movement at Netflix
By Guil Pires, Jennifer Prince, Jose Camacho, Ken Kurzweil, Phanindra Chunduru
Background
In a previous post, we introduced Data Bridge, a unified management plane for batch Data Movement at Netflix. Historically, several bespoke Data Movement connectors were developed across different engineering organizations to fulfill their specific requirements. Over the last few years, the Data Movement team has started centralizing these offerings through an abstraction that provides a catalog of connectors, along with simple UI and APIs to initiate Data Movement jobs.
One such case is the Cassandra to Iceberg connector. Apache Cassandra powers mission critical applications at Netflix, including Member, Billing, Recommendations, Subscriptions and many more. These use cases heavily leverage Data Movement to Apache Iceberg for many analytics and operational tasks, and central to this movement was a connector for Cassandra to Iceberg built in-house named Casspactor. As many Cassandra based Data Abstractions emerged, such as Key Value, Time Series and Graph — the need for larger and more complex Data Movement with transformations became more critical to the business.
Data movements are fundamentally fulfilled by leveraging the existing Cassandra backup infrastructure. Regularly scheduled backups are performed directly on the Apache Cassandra nodes, via a sidecar process managing the upload of all necessary SSTables and associated Metadata files directly into Amazon S3. When a Data Movement job is initiated, the job constructs the specific backup structure it needs by referencing the S3 based metadata, allowing it to precisely locate the SSTable files. The engine then downloads these files, performs the required mutation compaction and processing, and finally writes the fully transformed, compacted data directly into the target Apache Iceberg tables.
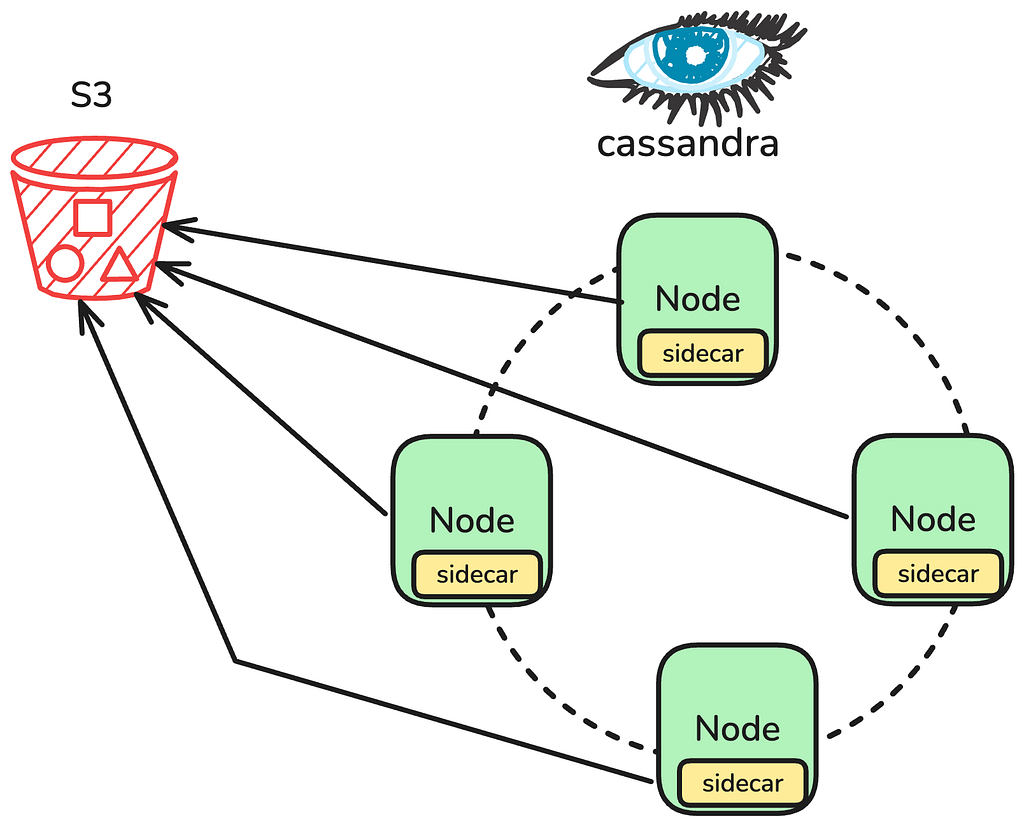
Casspactor: The Engine We Outgrew
Casspactor processed roughly 1,200 data movements per day, transferring approximately 3 PB of data from Apache Cassandra into Apache Iceberg tables. It served some of the most critical workloads at Netflix. For years, it worked. Then, two compounding challenges made it clear we needed a fundamentally different architecture.
Fragile Metadata Dependencies
Before Casspactor could move a single record, it needed to answer a deceptively simple question: which backup exists, is it complete, and what does it contain?
Casspactor assembled this answer from multiple independent systems:
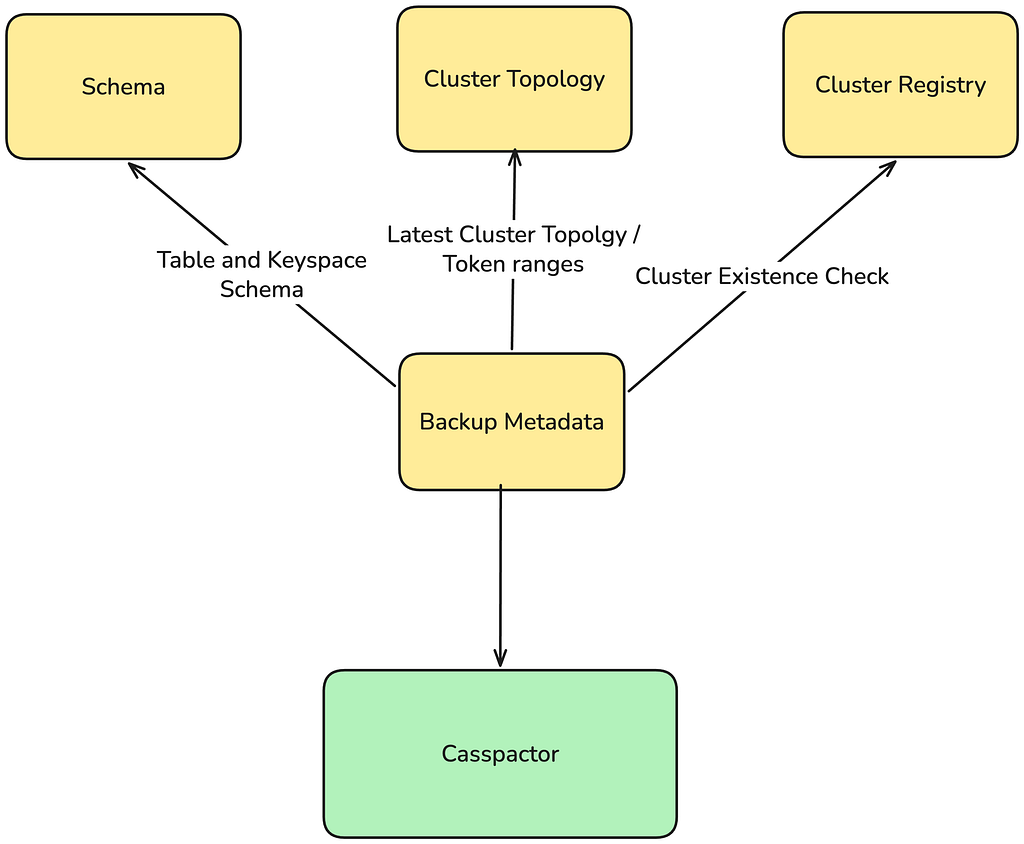
Each system had its own failure modes, update cadences, and accuracy guarantees. Casspactor’s view of the world was a composite, and composites diverge from reality.
Metadata fell out of sync with actual backups, causing Casspactor to read stale or incorrect data silently. Routine maintenance on the Cassandra Clusters triggered uncoordinated snapshots, and because Casspactor required all nodes in a region to snapshot at the same clock second, a single node replacement could break data movement for an entire region.
The fix was hiding in plain sight. The answer to “which backup exists and is it complete?” already lived in the backup storage layer (Amazon S3) itself. By reading metadata directly from the backup files, we could replace the entire dependency chain with a single source of truth.
Every Connector Inherited Casspactor’s Limitations
Cassandra at Netflix does not just store raw tables. It backs higher level data abstractions, such as Key Value, Time Series, and others, each with its own data model, access patterns, and semantics. When any of these abstractions needed to move data to Iceberg, they all funneled through Casspactor.
Every abstraction inherited Casspactor’s constraints:
- Skewed partition failures: Casspactor could not handle tables with large partitions, a common pattern in Key Value and Time Series workloads. Jobs crashed with out-of-memory errors on some of Netflix’s largest datasets.
- No data model awareness: Casspactor moved raw Cassandra tables as is. Connectors for Key Value and other abstractions had to bolt on post processing to reconstruct their data models from the raw output — extra cost, extra complexity, and an extra surface for failures.
- Intermediate table bloat: Casspactor wrote to an intermediate Iceberg table before producing the final output. The Key Value connector added another intermediate table and a snapshots table. Connectors for abstractions on top of Key Value added even more. This compounded into significant storage cost overhead.
- Inability to Time Travel: by relying on multiple services to compose a backup unit, Casspactor was unable to restore prior backups in the event of cluster Topology or Keyspace schema changes.
- Monolithic design: Casspactor was built as a single connector, not as an engine. There was no way to build a family of purpose built connectors on a shared foundation.
We needed something fundamentally different: an engine that reads directly from backups in S3, produces standard Spark DataFrames, and lets each data abstraction build its own connector with full awareness of its data model. One foundation, many connectors.
The New Stack: A Layered Architecture
The new architecture, built upon the foundation of Apache Cassandra Analytics and the in-house Move Data framework, represents a fundamental shift toward a layered, purpose-built stack designed for reuse and maintainability. This new engine was conceived with clear separation of concerns, moving away from Casspactor’s monolithic design. The architecture is intentionally layered with the foundation being a core S3 reading capability: the Cassandra Analytics Wrapper, which is built on top of the Open Source Cassandra Analytics with Netflix’s internal backup representation and an S3 Client.
This layer handles the raw data retrieval from backups, translating it into standard Spark DataFrames. Sitting atop this foundation is a “Connector Factory” model, via both Java UDFs and transforms which allows individual data abstractions (Key Value, Time Series, others) to build highly optimized, data model aware connectors that process the generic Spark DataFrames, avoiding the need for complex, expensive, and failure-prone post-processing steps. This layered approach ensures that improvements to the core reading engine benefit all connectors, while the connectors themselves are focused solely on data transformation.
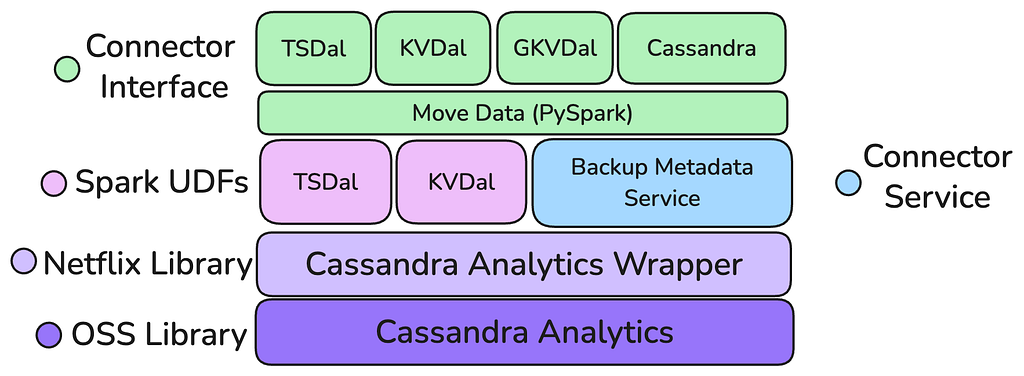
- Handles Skewed Partitions: By moving the mutation compaction and processing to the Executor level within Spark, the new engine can efficiently handle tables with highly skewed or wide partitions, a major pain point for Casspactor. Crucially, this processing occurs without excessive data shuffling, preventing out-of-memory errors and enabling reliable movement of Netflix’s largest datasets.
- Operates at Spark DataFrames (No Intermediary Tables): The new architecture directly generates standard Spark DataFrames from the Cassandra backups. This eliminates the need for Casspactor’s costly, multi-stage intermediate Iceberg tables, which led to storage bloat and operational complexity. This native DataFrame operation enables the “Connector Factory” by providing a universal, easily consumable interface for building diverse, model specific connectors.
- Jobs Auto Size: The engine integrates intelligent auto-sizing capabilities, allowing jobs to dynamically adjust resource consumption based on the source table’s characteristics. This removes the burden of manual tuning from engineering teams, ensuring optimal performance and cost efficiency without sacrificing reliability.
- Reduced Dependencies: By reading metadata directly from the backup files stored in S3, the new stack removes the fragile, multi-service dependency chain that plagued Casspactor. S3 becomes the single, authoritative source of truth for backup existence and completeness, vastly improving data movement reliability and consistency.
- Time Travel: A critical feature of the new stack is the ability to process the schema, cluster topology, and data as a cohesive unit at a specific point in time. This capability provides robust time travel functionality, essential for auditing, debugging, disaster recovery and reproducing past data states.
- Performance: Collectively, these architectural improvements, including native DataFrame processing, optimized partition handling, and streamlined metadata retrieval have resulted in notable performance gains, reducing overall data movement execution runtime and cost compared to the legacy Casspactor system.
- Cost: by eliminating intermediary Iceberg tables and efficient SSTable compaction on Executors, the new stack needs a significantly smaller storage and compute footprint leading to significant cost savings in the order of USD millions.
The Journey Towards a Safe Migration
The successful validation of the new stack was the critical first step, but it only marked the beginning of the most challenging phase: the migration. Large scale data migrations are inherently complex, high-risk undertakings that can be time consuming and often result in customer frustration and service disruption. To navigate the high stakes of decommissioning a mission-critical system like Casspactor and seamlessly replacing it, we needed a strategy that prioritized reliability and transparency above all else.
The migration was fundamentally enabled by a Like-for-Like strategy, which served as the cornerstone of our Platform Engineering philosophy, abstracting complexity. The core tenet was to maintain absolute consistency across the user-facing interface, the output contract, and the final data artifact. This meant ensuring that the data movement parameters defined via the Data Bridge abstraction remained unchanged, and, critically, the schema, metadata, and data within the destination Iceberg tables were identical to the legacy output. By preserving these external contracts, we eliminated the need for complex, time-consuming coordination with dozens of internal teams who relied on these data pipelines. This approach transformed the migration from a distributed, high-risk, multi-team effort into an internal platform implementation detail, allowing us to achieve a transparent, zero-impact transition and accelerate the retirement of the legacy system without requiring any code changes or validation from downstream users.
To navigate this migration, we developed a strategy anchored by three core pillars that serve as a blueprint for successful, large-scale data migrations:
- Validation: Establishing and maintaining absolute confidence in data consistency through rigorous, ongoing validation.
- Visibility: Instrumenting every part of the system to provide a clear, real-time understanding of migration progress and system health.
- Safety: Ensuring user impact is minimized or eliminated, despite the inevitable system failures, by leveraging abstractions and robust fallbacks.
The next section will provide a detailed exploration of these key pillars.
Pillar 1: Validation
Trust is earned, and in data migration, it is earned one row at a time. The first pillar is the most critical: providing a measurable guarantee to users and partners that the data produced by the new system is an exact, row-by-row replica of the data produced by the old one.
Our foundational tactic was deploying the new Move Data connector in a “shadow” testing that ran in parallel with the production Casspactor jobs. This allowed us to validate the new system with real-world, production workloads without any customer impact.
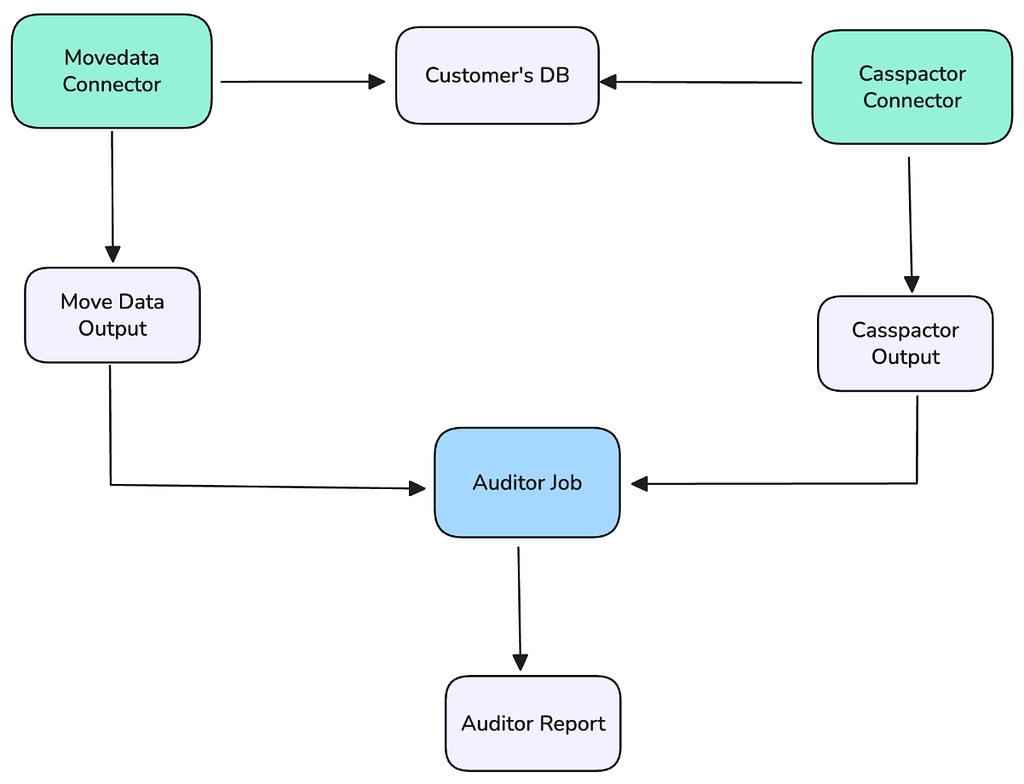
- Let C be the set of rows in the legacy Casspactor output (Iceberg table).
- Let M be the set of rows in the new Move Data output (Iceberg table).
The test for trust: prove that C = M. This required continuously checking for two conditions:
- Rows in C but not in M (C-M): The new system missed data.
- Rows in M but not in C (M-C): The new system introduced phantom or erroneous data.
Any result where the cardinality of these difference sets (the number of differing rows) was greater than zero triggered an immediate, high-priority investigation. The target was 100% similarity.
Uncovering and Resolving Disparities
The shadow mode quickly became a powerful forensic tool, exposing “unknown unknowns”, subtle discrepancies that were not bugs in the new system but rather differences in behavior between the new and old systems. Resolving these was the core work of building trust. For each problem we initiated an investigation log where we captured the details, logs, queries that allowed us to diagnose. Based on the assessment the issues were categorized so that similar differences on other datasets were later resolved affecting many of the shadow pipelines.
Maintaining an investigation log was critical to organize the outstanding issues and effectively communicate to stakeholders the progress and confidence of the new connector so that we effectively measure the appropriate level of “confidence” to initiate the migration.
We observed differences in how connectors leverage reference timestamps for Time-to-Live, Consistency Levels, backup selection, and various internal business logic. This continuous, data-driven cycle of discovery and resolution was the mechanism by which we built confidence in the new architecture.
Pillar 2: Visibility
Trust is built in the background, but an active migration requires real-time insight: Visibility. The second pillar involves instrumenting the system to provide an unambiguous, clear understanding of operational health and migration progress.
We extended our instrumentation to the overall migration workflow and its dependencies:
- Dashboards: We created centralized dashboards to track migration status, visualizing the total number of data movements migrated versus those remaining. The dashboards tracked execution status, average runtime, and cost comparisons between the two connectors.
- Dependency Tracking: Since the new system relied on a new set of APIs to fetch backup metadata, we implemented detailed metrics for failures to keep track of the APIs or dependencies failed.
- Alerting: Proactive alerts were set up for job failures (Move Data or Casspactor), failures on Move Data that triggered a fallback to Casspactor or any data discrepancy being detected.
This comprehensive instrumentation allowed the team to be proactive, fix issues as they emerged during the migration, and gain the necessary confidence to accelerate the migration timeline.
Pillar 3: Safety
Even with perfect data correctness and enhanced visibility, the third pillar, Safety is required for a zero-impact migration. The challenge is ensuring that when a system inevitably fails, the user experience is uninterrupted. Our strategy centered on decoupling the user’s workflow from the underlying connector implementation.
Leveraging Abstraction: The Decider Pattern
To achieve a transparent swap, we leveraged the Maestro workflow orchestration platform to implement the Decider pattern:
- Data Movement Abstraction: From a user’s perspective, their Data Movement job definition remained the same.
- The Decider Step: Internally the workflow responsible to execute the job was modified to include a Decider step. This step took the data movement parameters (source cluster, table name, destination) and invoked a control plane: Connector Controller.
- Connector Controller as the Registry: The control plane served as the dynamic registry. Based on the migration cohort and the data movement attributes, it determined and reported the appropriate connector to use either Casspactor (legacy) or Move Data (new).
This abstraction gave our team complete control. We could upgrade or rollback any connector for any data movement instantly by simply updating a configuration in the controller, with zero modification required to the thousands of downstream customer workflows. Crucially, this abstraction guaranteed the critical safety net: a conditional step in the Maestro workflow logic ensured that if the Move Data step fails, it would immediately execute the Casspactor step.
This pattern would increase the chances that the user’s data movement completes successfully, even if the new connector encountered a bug or transient failure during the initial rollout phases. User impact was completely eliminated; they might see a slightly longer runtime in the event of a failure and fallback, but they would never see a migration failure or suffer from stale data.
Beyond the workflow, the new system architecture itself was inherently more resilient. By building the new data movement connector on Cassandra Analytics and reading backups directly from S3, we removed fragile dependencies on deprecated internal services.
Conclusion
The migration from Casspactor to the new, layered architecture built on Cassandra Analytics and the Move Data connector was more than a typical “tech debt” project; it was a fundamental shift in our approach to data movement reliability and scalability at Netflix.
The legacy system, while serving us well for years, was ultimately constrained by monolithic design, fragile metadata dependencies, and an inability to handle the complexity of modern data abstractions. The new stack resolves these issues by delivering a robust, cost-efficient, and inherently more resilient solution that reads directly from S3, handles wide partitions gracefully, and eliminates costly intermediate tables.
Our blueprint for the migration, anchored by the three pillars of Validation, Visibility, and Safety, ensured a transparent and high-confidence transition. Through rigorous shadow testing and a data-driven audit framework, we achieved the desired data consistency. Enhanced dashboards and alerting provided the real-time operational insight necessary to manage risk. Most critically, the implementation of the Decider pattern within our workflow abstraction minimized the impact for all downstream users.
This successful migration validates a core philosophy: by abstracting complexity at the platform level, we can perform large system migrations without burdening our product engineering partners. The new foundation is now ready to support the next generation of Netflix’s data abstractions.
Looking ahead
This foundational work on the Cassandra Data Movement stack has done more than just replace a legacy system: it has become an accelerator for innovation across the entire Data Movement organization. By providing a reliable, performant engine that standardizes data retrieval into Spark DataFrames, we’ve enabled the rapid development of new, highly optimized connectors. This new “Connector Factory” approach has already delivered a dedicated Key-Value to Iceberg and Time Series connectors, both of which are fully aware of their respective data models, eliminating costly post-processing. This architecture is also paving the way for ambitious new initiatives, including the development of a solution for bulk loading data into Cassandra itself, effectively completing the data movement cycle, and enabling safer fleetwide connector rollout with canaries inspired by the Decider Pattern.
We are incredibly grateful for the extensive collaboration among the Data Movement, Data Bridge, Online Data Stores, Membership, Billing, Subscriber and Ads platform teams at Netflix; this work simply couldn’t have been accomplished without their partnership!
The Evolution of Cassandra Data Movement at Netflix was originally published in Netflix TechBlog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Instaclustr product update: June 2026
Here’s a roundup of the latest features and updates that we’ve recently released.
If you have any particular feature requests or enhancement ideas that you would like to see, please get in touch with us.
Major announcements AI Search for OpenSearch is now generally available on the NetApp Instaclustr Managed PlatformAI Search for OpenSearch is generally available on the NetApp Instaclustr Managed Platform. It brings semantic search, hybrid search, and retrieval-augmented generation (RAG) without the complexity of managing software, infrastructure, or operational management. General availability expands on the public preview, adding support for external LLM and embedding services such as Amazon Bedrock and OpenAI for enterprise search, e-commerce, support chatbots, and observability-style use cases. Unlock new possibilities with AI search—learn more.
Introducing Kafka Client Telemetry: Centralized client metrics for Instaclustr Managed Apache Kafka®NetApp is introducing Client Telemetry for Instaclustr for Apache Kafka®, designed to deliver broker-integrated visibility into Kafka client and application-level metrics, with telemetry export and centralized collection. Instaclustr for Apache Kafka users can gain visibility into client behavior such as connection status, request rates, error rates, and latency from the broker, simplifying monitoring and supporting a holistic view of client interactions. Compliant Kafka clients collect metrics and push them to the brokers; brokers use an OpenTelemetry Collector to forward metrics to a customer-specified destination, with Prometheus 3.0+ and Datadog supported in this initial release.
Powering low-latency analytics with ClickHouse® and Amazon FSxInstaclustr Managed ClickHouse integrated with Amazon FSx for NetApp ONTAP is built to run analytical queries directly on file-based data that can transparently tier to lower-cost capacity, without relying on extra staging layers, ingestion pipelines, or format-specific copies to make data queryable. The integration now supports deployments where compute and storage can reside in different VPCs or AWS accounts, enabling flexible, enterprise-grade architectures with consistent storage access across network and account boundaries.
Other significant changes Apache Cassandra®- Self-service iccassandra password reset — customers can now reset their iccassandra database password directly from the console via the Connection Info page, eliminating the need to raise a support ticket. The new password is displayed for 5 days before being automatically removed.
- Released Apache Cassandra v4.1.10 into General Availability on the NetApp Instaclustr Managed Platform, delivering a stability-focused patch release, while deprecating Apache Cassandra 4.1.9.
- Kafka and Kafka Connect 3.9.2 released to General Availability.
- Kafka and Kafka Connect 4.1.2 released to General Availability.
- Karapace Schema Registry 5.2.0 and Karapace Rest Proxy 5.2.0 are added support for Kafka clusters.
- ClickHouse v25.8.24 released to General Availability.
- New c7g.8xlarge node size on the AWS provider has been added to support OpenSearch clusters.
- OpenSearch 3.5.0 released to General Availability.
- AI Search is now available on the free trial.
- PostgreSQL 18.3, 17.9, and 16.13 and PgBouncer 1.25.1 released to General Availability.
- The new AWS region, ap-southeast-6 (New Zealand), has been added.
- Cluster tag management improvements — multiple enhancements to tag search, display, and validation in the console and API, including prevention of duplicate tag keys for better data consistency.
- We’re preparing to introduce GPU nodes for OpenSearch on the NetApp Instaclustr Managed Platform, bringing dedicated machine learning capabilities directly into your managed clusters. With GPU nodes, vector indexing can be up to 10x faster and CPU load is reduced, freeing cluster capacity for mission-critical workloads. Additionally, GPUs offer superior cost-efficiency compared to traditional CPU-based vector indexing, driving down the total cost of ownership.
- We’re close to launching PostgreSQL® integrated with FSx for NetApp ONTAP (FSxN) into GA, now including NVMe support—designed to deliver improved throughput, up to 20% observed greater throughput than we achieved with our public preview. This enhancement combines enterprise-grade PostgreSQL with FSxN’s scalable, cost-efficient storage for better cost, performance, and flexibility, while enabling ONTAP snapshots for backups, mirroring, and multi-region recovery—fast snapshot/restore and daily backups for large databases.
- NetApp Instaclustr plans to release the Remote MCP Gateway Service powered by AgentGateway on the Instaclustr Managed Platform. This service will let you, in minutes, provision and configure a production-ready Model Context Protocol gateway to provide LLM access to databases, application data infrastructure services, and REST APIs.
- Coming soon, NetApp Instaclustr will be launching the
Self-Service Bring Your Own Cloud (BYOC) feature for AWS, offering
a fully guided onboarding experience that allows customers to
connect their AWS accounts and begin deploying managed clusters
directly from the console — making it faster and easier for
customers who prefer to run clusters in their own cloud
environments.
Cluster DNS will soon be available for Apache Cassandra and Apache Kafka clusters on AWS allowing you to connect to your applications using simple, stable hostnames instead of long lists of IP addresses. When node IPs change due to scaling, replacement, or maintenance there is no longer a need to update client configuration.
- Need an end-to-end pattern for streaming analytics on AWS? The same-day three-part series How to build a streaming analytics pipeline with Terraform and Instaclustr, Part 1: Setting up your first Kafka® cluster, Part 2: Designing the complete data pipeline, and Part 3: Integrating with AWS VPC show how to stand up Kafka with Terraform, connect ClickHouse and Kafka Connect into a real pipeline, and finish with VPC integration for secure networking. Together the posts bridge provisioning, data flow design, and cloud networking without skipping the glue work that usually stalls proof-of-concepts.
- Apache Kafka 4.1.0 introduces the Streams Rebalance Protocol in early access for Kafka Streams: a broker-driven assignment model that eliminates client-side coordination, reduces “stop-the-world” rebalance pauses, and delivers smoother task assignment as Streams applications scale horizontally. For a walkthrough of when you need it, how to enable it, and what to expect, see What’s new in Kafka® 4.1.0? Introducing the new Streams Rebalance Protocol.
- OpenSearch 3.6 release bundles a wide set of upstream changes: ML Commons AI agent improvement such as token usage tracking, k-NN vector search performance improvements including Lucene Better Binary Quantization, Dashboards updates across AI chat and Explore, and OpenSearch APM for observability. For a single walkthrough of those themes, see OpenSearch version 3.6 release: smart agents and fast search. We’re currently testing OpenSearch 3.6 for compatibility and security purposes. Keep an eye on our release blog for more information about when this exciting new release will be available on the managed platform.
If you have any questions or need further assistance with these enhancements to the Instaclustr Managed Platform, please contact us.
SAFE HARBOR STATEMENT: Any unreleased services or features referenced in this blog are not currently available and may not be made generally available on time or at all, as may be determined in NetApp’s sole discretion. Any such referenced services or features do not represent promises to deliver, commitments, or obligations of NetApp and may not be incorporated into any contract. Customers should make their purchase decisions based upon services and features that are currently generally available.
The post Instaclustr product update: June 2026 appeared first on Instaclustr.
Automate ScyllaDB X Cloud Clusters with Terraform
The ScyllaDB Cloud Terraform provider gives you infrastructure-as-code control over your clusters The ScyllaDB Cloud Terraform provider now supports ScyllaDB X Cloud. That means you can provision and manage elastic, autoscaling ScyllaDB clusters the same way you manage the rest of your infrastructure. The ScyllaDB Cloud Terraform Provider The provider lives atregistry.terraform.io/scylladb/scylladbcloud. You need
a ScyllaDB Cloud account and an API token from cloud.scylladb.com.
terraform { required_providers { scylladbcloud = { source =
"registry.terraform.io/scylladb/scylladbcloud" version = "~>
0.3" } } required_version = ">= 0.13" } provider "scylladbcloud"
{ token = var.scylladb_token } Pass the token through a
variable. What Is ScyllaDB X Cloud? ScyllaDB X Cloud is
ScyllaDB’s elastic cluster tier built on a tablets-based
architecture. Traditional ScyllaDB clusters use token ranges pinned
to nodes. Scaling them up or down means rebalancing large chunks of
data. X Cloud uses tablets, which are smaller, independently
moveable units of data. When you add or remove nodes, tablets
rebalance in parallel across the cluster, which makes scaling fast
and non-disruptive. In practice this means you can: Scale from 100K
to 2M ops/sec in minutes, not hours Push storage utilization up to
90% before scaling out (no wasted headroom) Scale-in when load
drops (pay for what you use) X Cloud also differs from standard
clusters in how you configure it in Terraform: instead of choosing
a fixed node type and count, you define a scaling
policy and let the platform decide the right size.
Provisioning an X Cloud Cluster Here is a complete cluster
resource: resource "scylladbcloud_cluster" "xcloud" { name =
"my-xcloud-cluster" cloud = "AWS" region = "us-east-1" cidr_block =
"172.31.0.0/16" scaling { instance_families = ["i8g"]
storage_policy { min_gb = 500 target_utilization = 0.75 }
vcpu_policy { min = 6 } } } The scaling block
is what makes this an X Cloud cluster. It is mutually exclusive
with the node_type and min_nodes fields
used by standard clusters (you use one or the other). Key Scaling
Parameters instance_families instance_families =
["i8g"] X Cloud scales within a single instance family. The
platform picks specific instance sizes within that family as load
changes. Sticking with instance_families rather than
listing explicit instance_types gives the autoscaler
more room to work with. If you do restrict it to specific types,
allow at least three different types to give the scaler meaningful
options. storage_policy.min_gb storage_policy { min_gb = 500
} The cluster will not scale below this physical storage
threshold. Set it when you know your dataset has a minimum size and
want to avoid scale-in churn. storage_policy.target_utilization
storage_policy { target_utilization = 0.75 } This is
the utilization level the autoscaler aims to maintain. The valid
range is 0.7–0.9 (default: 0.8). The scaler adds capacity when
utilization exceeds target by more than 5%, and removes capacity
when it falls more than 5% below target. For write-heavy workloads,
staying below 0.85 is a good baseline. It gives compaction and
repairs room to breathe. vcpu_policy.min vcpu_policy { min =
6 } The cluster will not scale below this vCPU count,
regardless of load. That’s good for latency-sensitive workloads
where you want compute headroom even at low traffic. Standard
Clusters (For Comparison) If you need a fixed-size cluster or
require multi-DC deployments (which will be supported soon), use
the standard configuration: resource "scylladbcloud_cluster"
"standard" { name = "my-standard-cluster" cloud = "AWS" region =
"us-east-1" node_type = "i3.large" min_nodes = 3 cidr_block =
"172.31.0.0/16" } Standard clusters use
node_type and min_nodes instead of a
scaling block. Outputs After apply, the provider
exposes: output "cluster_id" { value =
scylladbcloud_cluster.xcloud.cluster_id } output "datacenter" {
value = scylladbcloud_cluster.xcloud.datacenter } output
"node_dns_names" { value =
scylladbcloud_cluster.xcloud.node_dns_names }
node_dns_names provides the hostnames to pass to your
driver configuration. Wrapping Up The ScyllaDB Cloud Terraform
provider gives you infrastructure-as-code control over your
clusters. For X Cloud specifically, the scaling block
replaces the manual node sizing decisions. You just define the
baselines and the platform handles the rest. ScyllaDB’s
tablets-based architecture means scale events are fast enough to
respond “just-in-time” to real traffic changes – so you don’t need
to overprovision for peak capacity just in case. For more details,
see the full provider documentation at
registry.terraform.io/providers/scylladb/scylladbcloud.