The Evolution of Cassandra Data Movement at Netflix
By Guil Pires, Jennifer Prince, Jose Camacho, Ken Kurzweil, Phanindra Chunduru
Background
In a previous post, we introduced Data Bridge, a unified management plane for batch Data Movement at Netflix. Historically, several bespoke Data Movement connectors were developed across different engineering organizations to fulfill their specific requirements. Over the last few years, the Data Movement team has started centralizing these offerings through an abstraction that provides a catalog of connectors, along with simple UI and APIs to initiate Data Movement jobs.
One such case is the Cassandra to Iceberg connector. Apache Cassandra powers mission critical applications at Netflix, including Member, Billing, Recommendations, Subscriptions and many more. These use cases heavily leverage Data Movement to Apache Iceberg for many analytics and operational tasks, and central to this movement was a connector for Cassandra to Iceberg built in-house named Casspactor. As many Cassandra based Data Abstractions emerged, such as Key Value, Time Series and Graph — the need for larger and more complex Data Movement with transformations became more critical to the business.
Data movements are fundamentally fulfilled by leveraging the existing Cassandra backup infrastructure. Regularly scheduled backups are performed directly on the Apache Cassandra nodes, via a sidecar process managing the upload of all necessary SSTables and associated Metadata files directly into Amazon S3. When a Data Movement job is initiated, the job constructs the specific backup structure it needs by referencing the S3 based metadata, allowing it to precisely locate the SSTable files. The engine then downloads these files, performs the required mutation compaction and processing, and finally writes the fully transformed, compacted data directly into the target Apache Iceberg tables.
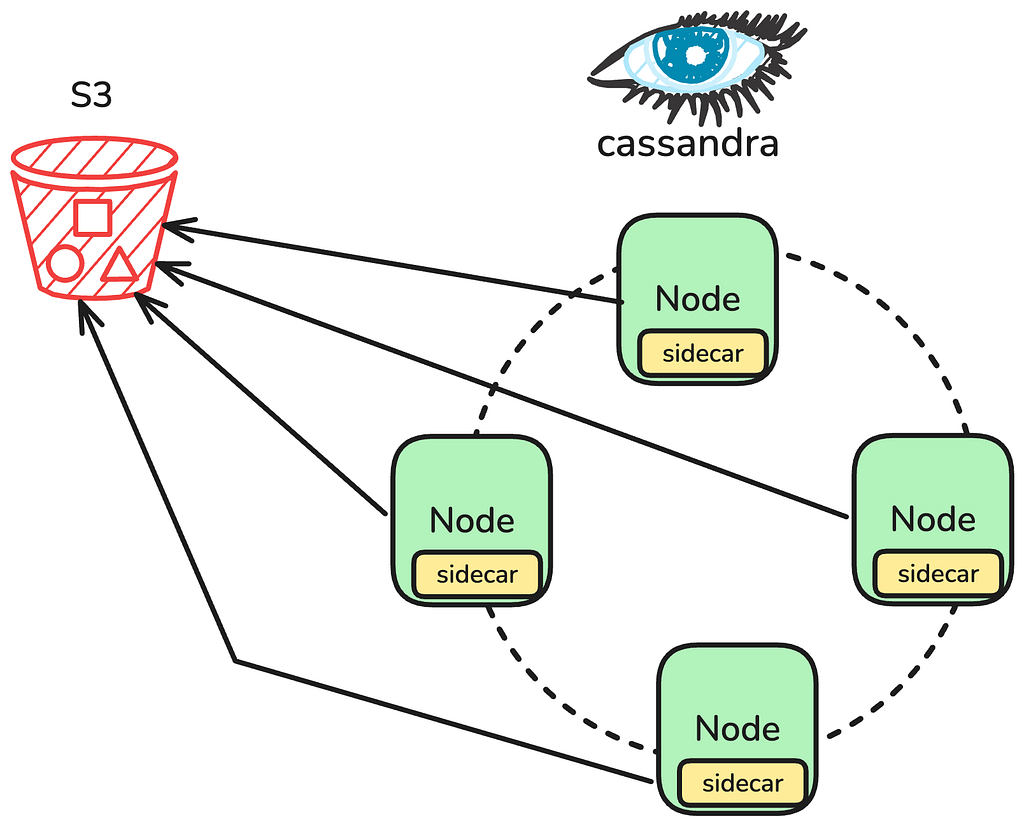
Casspactor: The Engine We Outgrew
Casspactor processed roughly 1,200 data movements per day, transferring approximately 3 PB of data from Apache Cassandra into Apache Iceberg tables. It served some of the most critical workloads at Netflix. For years, it worked. Then, two compounding challenges made it clear we needed a fundamentally different architecture.
Fragile Metadata Dependencies
Before Casspactor could move a single record, it needed to answer a deceptively simple question: which backup exists, is it complete, and what does it contain?
Casspactor assembled this answer from multiple independent systems:
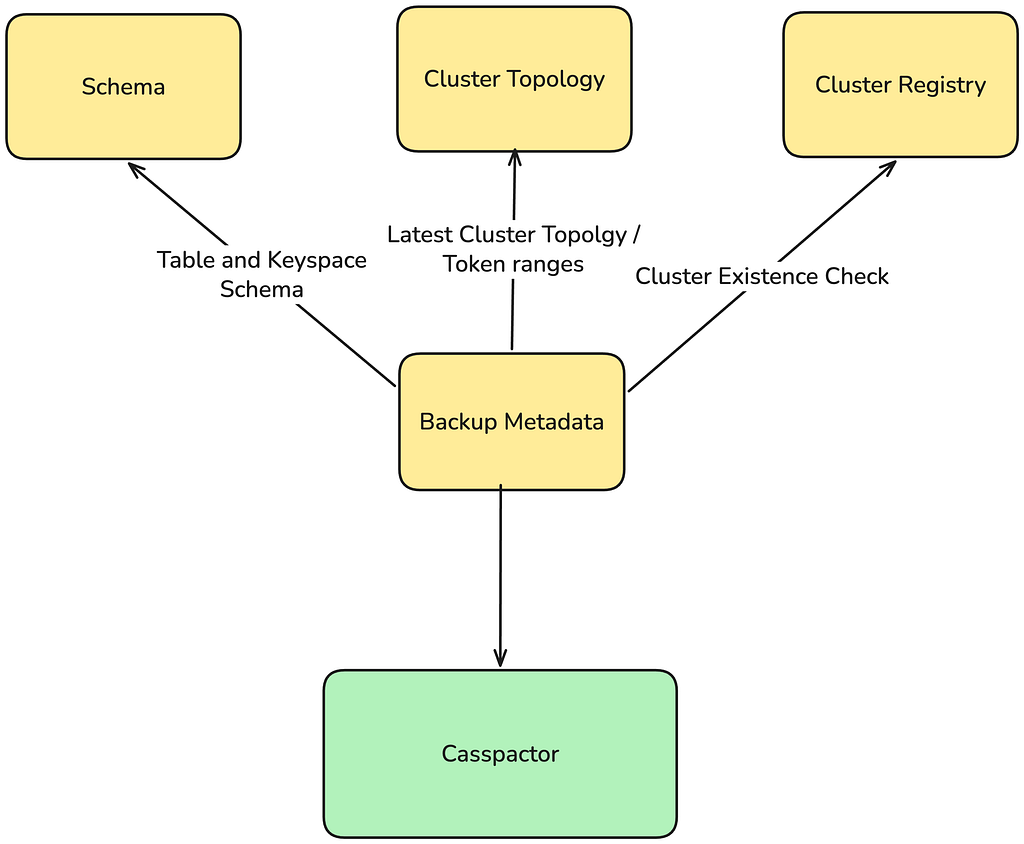
Each system had its own failure modes, update cadences, and accuracy guarantees. Casspactor’s view of the world was a composite, and composites diverge from reality.
Metadata fell out of sync with actual backups, causing Casspactor to read stale or incorrect data silently. Routine maintenance on the Cassandra Clusters triggered uncoordinated snapshots, and because Casspactor required all nodes in a region to snapshot at the same clock second, a single node replacement could break data movement for an entire region.
The fix was hiding in plain sight. The answer to “which backup exists and is it complete?” already lived in the backup storage layer (Amazon S3) itself. By reading metadata directly from the backup files, we could replace the entire dependency chain with a single source of truth.
Every Connector Inherited Casspactor’s Limitations
Cassandra at Netflix does not just store raw tables. It backs higher level data abstractions, such as Key Value, Time Series, and others, each with its own data model, access patterns, and semantics. When any of these abstractions needed to move data to Iceberg, they all funneled through Casspactor.
Every abstraction inherited Casspactor’s constraints:
- Skewed partition failures: Casspactor could not handle tables with large partitions, a common pattern in Key Value and Time Series workloads. Jobs crashed with out-of-memory errors on some of Netflix’s largest datasets.
- No data model awareness: Casspactor moved raw Cassandra tables as is. Connectors for Key Value and other abstractions had to bolt on post processing to reconstruct their data models from the raw output — extra cost, extra complexity, and an extra surface for failures.
- Intermediate table bloat: Casspactor wrote to an intermediate Iceberg table before producing the final output. The Key Value connector added another intermediate table and a snapshots table. Connectors for abstractions on top of Key Value added even more. This compounded into significant storage cost overhead.
- Inability to Time Travel: by relying on multiple services to compose a backup unit, Casspactor was unable to restore prior backups in the event of cluster Topology or Keyspace schema changes.
- Monolithic design: Casspactor was built as a single connector, not as an engine. There was no way to build a family of purpose built connectors on a shared foundation.
We needed something fundamentally different: an engine that reads directly from backups in S3, produces standard Spark DataFrames, and lets each data abstraction build its own connector with full awareness of its data model. One foundation, many connectors.
The New Stack: A Layered Architecture
The new architecture, built upon the foundation of Apache Cassandra Analytics and the in-house Move Data framework, represents a fundamental shift toward a layered, purpose-built stack designed for reuse and maintainability. This new engine was conceived with clear separation of concerns, moving away from Casspactor’s monolithic design. The architecture is intentionally layered with the foundation being a core S3 reading capability: the Cassandra Analytics Wrapper, which is built on top of the Open Source Cassandra Analytics with Netflix’s internal backup representation and an S3 Client.
This layer handles the raw data retrieval from backups, translating it into standard Spark DataFrames. Sitting atop this foundation is a “Connector Factory” model, via both Java UDFs and transforms which allows individual data abstractions (Key Value, Time Series, others) to build highly optimized, data model aware connectors that process the generic Spark DataFrames, avoiding the need for complex, expensive, and failure-prone post-processing steps. This layered approach ensures that improvements to the core reading engine benefit all connectors, while the connectors themselves are focused solely on data transformation.
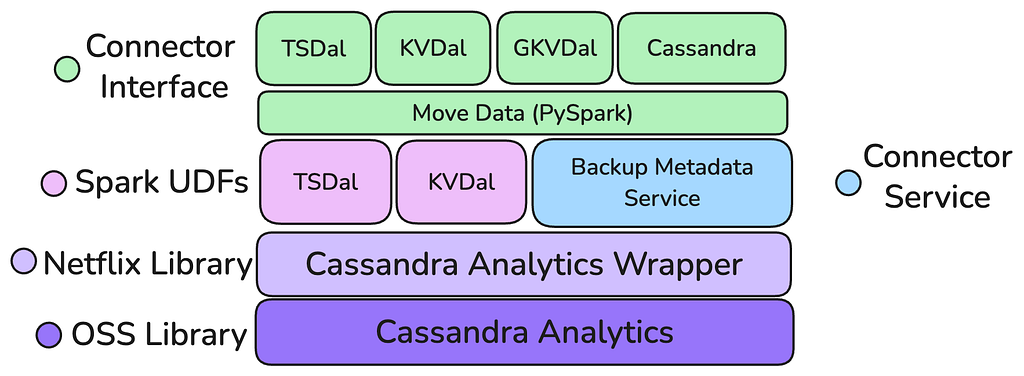
- Handles Skewed Partitions: By moving the mutation compaction and processing to the Executor level within Spark, the new engine can efficiently handle tables with highly skewed or wide partitions, a major pain point for Casspactor. Crucially, this processing occurs without excessive data shuffling, preventing out-of-memory errors and enabling reliable movement of Netflix’s largest datasets.
- Operates at Spark DataFrames (No Intermediary Tables): The new architecture directly generates standard Spark DataFrames from the Cassandra backups. This eliminates the need for Casspactor’s costly, multi-stage intermediate Iceberg tables, which led to storage bloat and operational complexity. This native DataFrame operation enables the “Connector Factory” by providing a universal, easily consumable interface for building diverse, model specific connectors.
- Jobs Auto Size: The engine integrates intelligent auto-sizing capabilities, allowing jobs to dynamically adjust resource consumption based on the source table’s characteristics. This removes the burden of manual tuning from engineering teams, ensuring optimal performance and cost efficiency without sacrificing reliability.
- Reduced Dependencies: By reading metadata directly from the backup files stored in S3, the new stack removes the fragile, multi-service dependency chain that plagued Casspactor. S3 becomes the single, authoritative source of truth for backup existence and completeness, vastly improving data movement reliability and consistency.
- Time Travel: A critical feature of the new stack is the ability to process the schema, cluster topology, and data as a cohesive unit at a specific point in time. This capability provides robust time travel functionality, essential for auditing, debugging, disaster recovery and reproducing past data states.
- Performance: Collectively, these architectural improvements, including native DataFrame processing, optimized partition handling, and streamlined metadata retrieval have resulted in notable performance gains, reducing overall data movement execution runtime and cost compared to the legacy Casspactor system.
- Cost: by eliminating intermediary Iceberg tables and efficient SSTable compaction on Executors, the new stack needs a significantly smaller storage and compute footprint leading to significant cost savings in the order of USD millions.
The Journey Towards a Safe Migration
The successful validation of the new stack was the critical first step, but it only marked the beginning of the most challenging phase: the migration. Large scale data migrations are inherently complex, high-risk undertakings that can be time consuming and often result in customer frustration and service disruption. To navigate the high stakes of decommissioning a mission-critical system like Casspactor and seamlessly replacing it, we needed a strategy that prioritized reliability and transparency above all else.
The migration was fundamentally enabled by a Like-for-Like strategy, which served as the cornerstone of our Platform Engineering philosophy, abstracting complexity. The core tenet was to maintain absolute consistency across the user-facing interface, the output contract, and the final data artifact. This meant ensuring that the data movement parameters defined via the Data Bridge abstraction remained unchanged, and, critically, the schema, metadata, and data within the destination Iceberg tables were identical to the legacy output. By preserving these external contracts, we eliminated the need for complex, time-consuming coordination with dozens of internal teams who relied on these data pipelines. This approach transformed the migration from a distributed, high-risk, multi-team effort into an internal platform implementation detail, allowing us to achieve a transparent, zero-impact transition and accelerate the retirement of the legacy system without requiring any code changes or validation from downstream users.
To navigate this migration, we developed a strategy anchored by three core pillars that serve as a blueprint for successful, large-scale data migrations:
- Validation: Establishing and maintaining absolute confidence in data consistency through rigorous, ongoing validation.
- Visibility: Instrumenting every part of the system to provide a clear, real-time understanding of migration progress and system health.
- Safety: Ensuring user impact is minimized or eliminated, despite the inevitable system failures, by leveraging abstractions and robust fallbacks.
The next section will provide a detailed exploration of these key pillars.
Pillar 1: Validation
Trust is earned, and in data migration, it is earned one row at a time. The first pillar is the most critical: providing a measurable guarantee to users and partners that the data produced by the new system is an exact, row-by-row replica of the data produced by the old one.
Our foundational tactic was deploying the new Move Data connector in a “shadow” testing that ran in parallel with the production Casspactor jobs. This allowed us to validate the new system with real-world, production workloads without any customer impact.
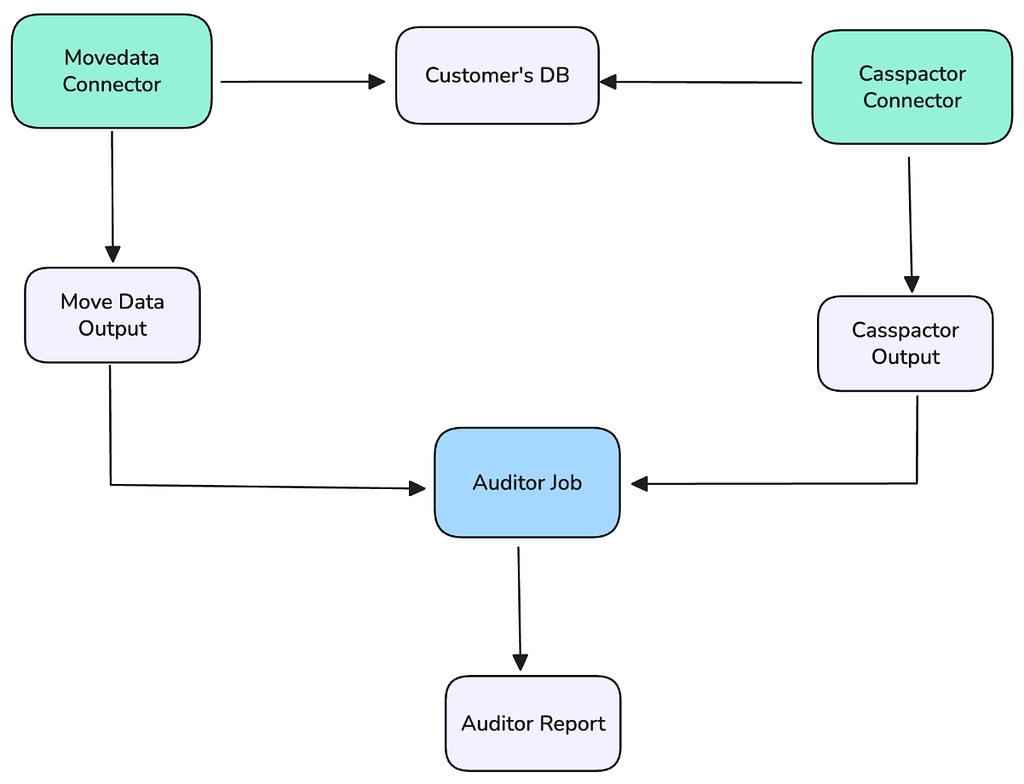
- Let C be the set of rows in the legacy Casspactor output (Iceberg table).
- Let M be the set of rows in the new Move Data output (Iceberg table).
The test for trust: prove that C = M. This required continuously checking for two conditions:
- Rows in C but not in M (C-M): The new system missed data.
- Rows in M but not in C (M-C): The new system introduced phantom or erroneous data.
Any result where the cardinality of these difference sets (the number of differing rows) was greater than zero triggered an immediate, high-priority investigation. The target was 100% similarity.
Uncovering and Resolving Disparities
The shadow mode quickly became a powerful forensic tool, exposing “unknown unknowns”, subtle discrepancies that were not bugs in the new system but rather differences in behavior between the new and old systems. Resolving these was the core work of building trust. For each problem we initiated an investigation log where we captured the details, logs, queries that allowed us to diagnose. Based on the assessment the issues were categorized so that similar differences on other datasets were later resolved affecting many of the shadow pipelines.
Maintaining an investigation log was critical to organize the outstanding issues and effectively communicate to stakeholders the progress and confidence of the new connector so that we effectively measure the appropriate level of “confidence” to initiate the migration.
We observed differences in how connectors leverage reference timestamps for Time-to-Live, Consistency Levels, backup selection, and various internal business logic. This continuous, data-driven cycle of discovery and resolution was the mechanism by which we built confidence in the new architecture.
Pillar 2: Visibility
Trust is built in the background, but an active migration requires real-time insight: Visibility. The second pillar involves instrumenting the system to provide an unambiguous, clear understanding of operational health and migration progress.
We extended our instrumentation to the overall migration workflow and its dependencies:
- Dashboards: We created centralized dashboards to track migration status, visualizing the total number of data movements migrated versus those remaining. The dashboards tracked execution status, average runtime, and cost comparisons between the two connectors.
- Dependency Tracking: Since the new system relied on a new set of APIs to fetch backup metadata, we implemented detailed metrics for failures to keep track of the APIs or dependencies failed.
- Alerting: Proactive alerts were set up for job failures (Move Data or Casspactor), failures on Move Data that triggered a fallback to Casspactor or any data discrepancy being detected.
This comprehensive instrumentation allowed the team to be proactive, fix issues as they emerged during the migration, and gain the necessary confidence to accelerate the migration timeline.
Pillar 3: Safety
Even with perfect data correctness and enhanced visibility, the third pillar, Safety is required for a zero-impact migration. The challenge is ensuring that when a system inevitably fails, the user experience is uninterrupted. Our strategy centered on decoupling the user’s workflow from the underlying connector implementation.
Leveraging Abstraction: The Decider Pattern
To achieve a transparent swap, we leveraged the Maestro workflow orchestration platform to implement the Decider pattern:
- Data Movement Abstraction: From a user’s perspective, their Data Movement job definition remained the same.
- The Decider Step: Internally the workflow responsible to execute the job was modified to include a Decider step. This step took the data movement parameters (source cluster, table name, destination) and invoked a control plane: Connector Controller.
- Connector Controller as the Registry: The control plane served as the dynamic registry. Based on the migration cohort and the data movement attributes, it determined and reported the appropriate connector to use either Casspactor (legacy) or Move Data (new).
This abstraction gave our team complete control. We could upgrade or rollback any connector for any data movement instantly by simply updating a configuration in the controller, with zero modification required to the thousands of downstream customer workflows. Crucially, this abstraction guaranteed the critical safety net: a conditional step in the Maestro workflow logic ensured that if the Move Data step fails, it would immediately execute the Casspactor step.
This pattern would increase the chances that the user’s data movement completes successfully, even if the new connector encountered a bug or transient failure during the initial rollout phases. User impact was completely eliminated; they might see a slightly longer runtime in the event of a failure and fallback, but they would never see a migration failure or suffer from stale data.
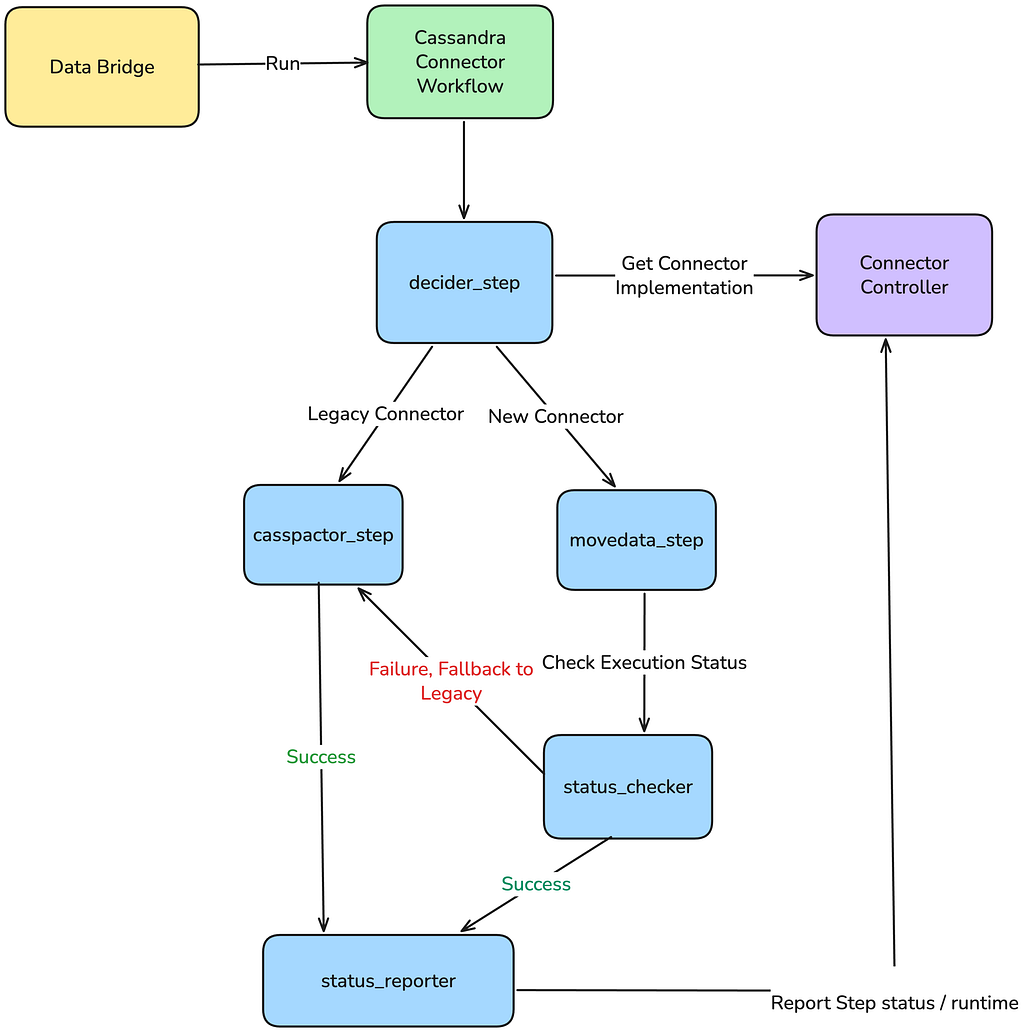
Beyond the workflow, the new system architecture itself was inherently more resilient. By building the new data movement connector on Cassandra Analytics and reading backups directly from S3, we removed fragile dependencies on deprecated internal services.
Conclusion
The migration from Casspactor to the new, layered architecture built on Cassandra Analytics and the Move Data connector was more than a typical “tech debt” project; it was a fundamental shift in our approach to data movement reliability and scalability at Netflix.
The legacy system, while serving us well for years, was ultimately constrained by monolithic design, fragile metadata dependencies, and an inability to handle the complexity of modern data abstractions. The new stack resolves these issues by delivering a robust, cost-efficient, and inherently more resilient solution that reads directly from S3, handles wide partitions gracefully, and eliminates costly intermediate tables.
Our blueprint for the migration, anchored by the three pillars of Validation, Visibility, and Safety, ensured a transparent and high-confidence transition. Through rigorous shadow testing and a data-driven audit framework, we achieved the desired data consistency. Enhanced dashboards and alerting provided the real-time operational insight necessary to manage risk. Most critically, the implementation of the Decider pattern within our workflow abstraction minimized the impact for all downstream users.
This successful migration validates a core philosophy: by abstracting complexity at the platform level, we can perform large system migrations without burdening our product engineering partners. The new foundation is now ready to support the next generation of Netflix’s data abstractions.
Looking ahead
This foundational work on the Cassandra Data Movement stack has done more than just replace a legacy system: it has become an accelerator for innovation across the entire Data Movement organization. By providing a reliable, performant engine that standardizes data retrieval into Spark DataFrames, we’ve enabled the rapid development of new, highly optimized connectors. This new “Connector Factory” approach has already delivered a dedicated Key-Value to Iceberg and Time Series connectors, both of which are fully aware of their respective data models, eliminating costly post-processing. This architecture is also paving the way for ambitious new initiatives, including the development of a solution for bulk loading data into Cassandra itself, effectively completing the data movement cycle, and enabling safer fleetwide connector rollout with canaries inspired by the Decider Pattern.
We are incredibly grateful for the extensive collaboration among the Data Movement, Data Bridge, Online Data Stores, Membership, Billing, Subscriber and Ads platform teams at Netflix; this work simply couldn’t have been accomplished without their partnership!
The Evolution of Cassandra Data Movement at Netflix was originally published in Netflix TechBlog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Instaclustr product update: June 2026
Here’s a roundup of the latest features and updates that we’ve recently released.
If you have any particular feature requests or enhancement ideas that you would like to see, please get in touch with us.
Major announcements AI Search for OpenSearch is now generally available on the NetApp Instaclustr Managed PlatformAI Search for OpenSearch is generally available on the NetApp Instaclustr Managed Platform. It brings semantic search, hybrid search, and retrieval-augmented generation (RAG) without the complexity of managing software, infrastructure, or operational management. General availability expands on the public preview, adding support for external LLM and embedding services such as Amazon Bedrock and OpenAI for enterprise search, e-commerce, support chatbots, and observability-style use cases. Unlock new possibilities with AI search—learn more.
Introducing Kafka Client Telemetry: Centralized client metrics for Instaclustr Managed Apache Kafka®NetApp is introducing Client Telemetry for Instaclustr for Apache Kafka®, designed to deliver broker-integrated visibility into Kafka client and application-level metrics, with telemetry export and centralized collection. Instaclustr for Apache Kafka users can gain visibility into client behavior such as connection status, request rates, error rates, and latency from the broker, simplifying monitoring and supporting a holistic view of client interactions. Compliant Kafka clients collect metrics and push them to the brokers; brokers use an OpenTelemetry Collector to forward metrics to a customer-specified destination, with Prometheus 3.0+ and Datadog supported in this initial release.
Powering low-latency analytics with ClickHouse® and Amazon FSxInstaclustr Managed ClickHouse integrated with Amazon FSx for NetApp ONTAP is built to run analytical queries directly on file-based data that can transparently tier to lower-cost capacity, without relying on extra staging layers, ingestion pipelines, or format-specific copies to make data queryable. The integration now supports deployments where compute and storage can reside in different VPCs or AWS accounts, enabling flexible, enterprise-grade architectures with consistent storage access across network and account boundaries.
Other significant changes Apache Cassandra®- Self-service iccassandra password reset — customers can now reset their iccassandra database password directly from the console via the Connection Info page, eliminating the need to raise a support ticket. The new password is displayed for 5 days before being automatically removed.
- Released Apache Cassandra v4.1.10 into General Availability on the NetApp Instaclustr Managed Platform, delivering a stability-focused patch release, while deprecating Apache Cassandra 4.1.9.
- Kafka and Kafka Connect 3.9.2 released to General Availability.
- Kafka and Kafka Connect 4.1.2 released to General Availability.
- Karapace Schema Registry 5.2.0 and Karapace Rest Proxy 5.2.0 are added support for Kafka clusters.
- ClickHouse v25.8.24 released to General Availability.
- New c7g.8xlarge node size on the AWS provider has been added to support OpenSearch clusters.
- OpenSearch 3.5.0 released to General Availability.
- AI Search is now available on the free trial.
- PostgreSQL 18.3, 17.9, and 16.13 and PgBouncer 1.25.1 released to General Availability.
- The new AWS region, ap-southeast-6 (New Zealand), has been added.
- Cluster tag management improvements — multiple enhancements to tag search, display, and validation in the console and API, including prevention of duplicate tag keys for better data consistency.
- We’re preparing to introduce GPU nodes for OpenSearch on the NetApp Instaclustr Managed Platform, bringing dedicated machine learning capabilities directly into your managed clusters. With GPU nodes, vector indexing can be up to 10x faster and CPU load is reduced, freeing cluster capacity for mission-critical workloads. Additionally, GPUs offer superior cost-efficiency compared to traditional CPU-based vector indexing, driving down the total cost of ownership.
- We’re close to launching PostgreSQL® integrated with FSx for NetApp ONTAP (FSxN) into GA, now including NVMe support—designed to deliver improved throughput, up to 20% observed greater throughput than we achieved with our public preview. This enhancement combines enterprise-grade PostgreSQL with FSxN’s scalable, cost-efficient storage for better cost, performance, and flexibility, while enabling ONTAP snapshots for backups, mirroring, and multi-region recovery—fast snapshot/restore and daily backups for large databases.
- NetApp Instaclustr plans to release the Remote MCP Gateway Service powered by AgentGateway on the Instaclustr Managed Platform. This service will let you, in minutes, provision and configure a production-ready Model Context Protocol gateway to provide LLM access to databases, application data infrastructure services, and REST APIs.
- Coming soon, NetApp Instaclustr will be launching the
Self-Service Bring Your Own Cloud (BYOC) feature for AWS, offering
a fully guided onboarding experience that allows customers to
connect their AWS accounts and begin deploying managed clusters
directly from the console — making it faster and easier for
customers who prefer to run clusters in their own cloud
environments.
Cluster DNS will soon be available for Apache Cassandra and Apache Kafka clusters on AWS allowing you to connect to your applications using simple, stable hostnames instead of long lists of IP addresses. When node IPs change due to scaling, replacement, or maintenance there is no longer a need to update client configuration.
- Need an end-to-end pattern for streaming analytics on AWS? The same-day three-part series How to build a streaming analytics pipeline with Terraform and Instaclustr, Part 1: Setting up your first Kafka® cluster, Part 2: Designing the complete data pipeline, and Part 3: Integrating with AWS VPC show how to stand up Kafka with Terraform, connect ClickHouse and Kafka Connect into a real pipeline, and finish with VPC integration for secure networking. Together the posts bridge provisioning, data flow design, and cloud networking without skipping the glue work that usually stalls proof-of-concepts.
- Apache Kafka 4.1.0 introduces the Streams Rebalance Protocol in early access for Kafka Streams: a broker-driven assignment model that eliminates client-side coordination, reduces “stop-the-world” rebalance pauses, and delivers smoother task assignment as Streams applications scale horizontally. For a walkthrough of when you need it, how to enable it, and what to expect, see What’s new in Kafka® 4.1.0? Introducing the new Streams Rebalance Protocol.
- OpenSearch 3.6 release bundles a wide set of upstream changes: ML Commons AI agent improvement such as token usage tracking, k-NN vector search performance improvements including Lucene Better Binary Quantization, Dashboards updates across AI chat and Explore, and OpenSearch APM for observability. For a single walkthrough of those themes, see OpenSearch version 3.6 release: smart agents and fast search. We’re currently testing OpenSearch 3.6 for compatibility and security purposes. Keep an eye on our release blog for more information about when this exciting new release will be available on the managed platform.
If you have any questions or need further assistance with these enhancements to the Instaclustr Managed Platform, please contact us.
SAFE HARBOR STATEMENT: Any unreleased services or features referenced in this blog are not currently available and may not be made generally available on time or at all, as may be determined in NetApp’s sole discretion. Any such referenced services or features do not represent promises to deliver, commitments, or obligations of NetApp and may not be incorporated into any contract. Customers should make their purchase decisions based upon services and features that are currently generally available.
The post Instaclustr product update: June 2026 appeared first on Instaclustr.
Automate ScyllaDB X Cloud Clusters with Terraform
The ScyllaDB Cloud Terraform provider gives you infrastructure-as-code control over your clusters The ScyllaDB Cloud Terraform provider now supports ScyllaDB X Cloud. That means you can provision and manage elastic, autoscaling ScyllaDB clusters the same way you manage the rest of your infrastructure. The ScyllaDB Cloud Terraform Provider The provider lives atregistry.terraform.io/scylladb/scylladbcloud. You need
a ScyllaDB Cloud account and an API token from cloud.scylladb.com.
terraform { required_providers { scylladbcloud = { source =
"registry.terraform.io/scylladb/scylladbcloud" version = "~>
0.3" } } required_version = ">= 0.13" } provider "scylladbcloud"
{ token = var.scylladb_token } Pass the token through a
variable. What Is ScyllaDB X Cloud? ScyllaDB X Cloud is
ScyllaDB’s elastic cluster tier built on a tablets-based
architecture. Traditional ScyllaDB clusters use token ranges pinned
to nodes. Scaling them up or down means rebalancing large chunks of
data. X Cloud uses tablets, which are smaller, independently
moveable units of data. When you add or remove nodes, tablets
rebalance in parallel across the cluster, which makes scaling fast
and non-disruptive. In practice this means you can: Scale from 100K
to 2M ops/sec in minutes, not hours Push storage utilization up to
90% before scaling out (no wasted headroom) Scale-in when load
drops (pay for what you use) X Cloud also differs from standard
clusters in how you configure it in Terraform: instead of choosing
a fixed node type and count, you define a scaling
policy and let the platform decide the right size.
Provisioning an X Cloud Cluster Here is a complete cluster
resource: resource "scylladbcloud_cluster" "xcloud" { name =
"my-xcloud-cluster" cloud = "AWS" region = "us-east-1" cidr_block =
"172.31.0.0/16" scaling { instance_families = ["i8g"]
storage_policy { min_gb = 500 target_utilization = 0.75 }
vcpu_policy { min = 6 } } } The scaling block
is what makes this an X Cloud cluster. It is mutually exclusive
with the node_type and min_nodes fields
used by standard clusters (you use one or the other). Key Scaling
Parameters instance_families instance_families =
["i8g"] X Cloud scales within a single instance family. The
platform picks specific instance sizes within that family as load
changes. Sticking with instance_families rather than
listing explicit instance_types gives the autoscaler
more room to work with. If you do restrict it to specific types,
allow at least three different types to give the scaler meaningful
options. storage_policy.min_gb storage_policy { min_gb = 500
} The cluster will not scale below this physical storage
threshold. Set it when you know your dataset has a minimum size and
want to avoid scale-in churn. storage_policy.target_utilization
storage_policy { target_utilization = 0.75 } This is
the utilization level the autoscaler aims to maintain. The valid
range is 0.7–0.9 (default: 0.8). The scaler adds capacity when
utilization exceeds target by more than 5%, and removes capacity
when it falls more than 5% below target. For write-heavy workloads,
staying below 0.85 is a good baseline. It gives compaction and
repairs room to breathe. vcpu_policy.min vcpu_policy { min =
6 } The cluster will not scale below this vCPU count,
regardless of load. That’s good for latency-sensitive workloads
where you want compute headroom even at low traffic. Standard
Clusters (For Comparison) If you need a fixed-size cluster or
require multi-DC deployments (which will be supported soon), use
the standard configuration: resource "scylladbcloud_cluster"
"standard" { name = "my-standard-cluster" cloud = "AWS" region =
"us-east-1" node_type = "i3.large" min_nodes = 3 cidr_block =
"172.31.0.0/16" } Standard clusters use
node_type and min_nodes instead of a
scaling block. Outputs After apply, the provider
exposes: output "cluster_id" { value =
scylladbcloud_cluster.xcloud.cluster_id } output "datacenter" {
value = scylladbcloud_cluster.xcloud.datacenter } output
"node_dns_names" { value =
scylladbcloud_cluster.xcloud.node_dns_names }
node_dns_names provides the hostnames to pass to your
driver configuration. Wrapping Up The ScyllaDB Cloud Terraform
provider gives you infrastructure-as-code control over your
clusters. For X Cloud specifically, the scaling block
replaces the manual node sizing decisions. You just define the
baselines and the platform handles the rest. ScyllaDB’s
tablets-based architecture means scale events are fast enough to
respond “just-in-time” to real traffic changes – so you don’t need
to overprovision for peak capacity just in case. For more details,
see the full provider documentation at
registry.terraform.io/providers/scylladb/scylladbcloud. ScyllaDB Customer Experience Spotlight: Faisal Saeed
Welcome to the second installment of a new blog series introducing some of the experts you might encounter when you work with ScyllaDB. (In the first, we met Tyler Denton, Solutions Architect). Today we’re featuring Faisal Saeed, Principal Customer Engineer on the Customer Experience team here at ScyllaDB. He lives in Singapore and has been at ScyllaDB for more than 2 years. Let’s learn a little about Faisal… What do you do here at ScyllaDB I have a hybrid role where I work with existing customers as their Principal Customer Engineer, helping them ensure their ScyllaDB Cloud / on-prem clusters are in good health and performing according to their expectations. Secondly, I work as a pre-sales Solutions Architect for clients who are not existing ScyllaDB customers and are evaluating ScyllaDB. Here, I often help with data modeling or planning their data migration from their existing database into ScyllaDB Enterprise / ScyllaDB Cloud clusters. Please share a little about your path to ScyllaDB I have worked in the IT industry for about 30 years and have extensive database experience. Before joining ScyllaDB, I was a Principal Solutions Architect with MariaDB for 6 years. Before that, I worked with ACI Worldwide as a database architect on projects for DBS Bank in Singapore. Before that, I spent many years at NCS, working as a database architect on DBS Bank projects. Tell me about one of the most interesting projects you’ve worked on here While I work with many amazing customers, the project I cherish the most is an in-house developed tool that automates ScyllaDB Enterprise/Cloud/X Cloud clusters with a single command, allowing the user to run various workloads and perform stress testing of multiple clusters. This is the ScyllaDB Automation Framework, and I have worked on this project for more than a year. This helps various team members in ScyllaDB with their day to day tasks, whether running a demo for a customer or simulating a customer use case. What’s the most impressive ScyllaDB feat you’ve seen a team accomplish If we talk about teams in ScyllaDB, X Cloud is an amazing ScyllaDB product that lets customers save costs while running at any scale. The team has done an outstanding job. Talking about customers, every one of them is unique in some way. JioStar from India uses ScyllaDB to support IPL, World Cup Cricket, and many other supporting events where millions of users concurrently log in to ScyllaDB clusters through their app — and ScyllaDB handles them gracefully without any lags. There are many others, but I can’t mention everyone. What do you like to do when you’re not working or on-call I spend time with my wife at home, go out for long walks, watch movies, and care for two bunnies who have been with us for more than 5 years. What’s your top tip for getting the most out of ScyllaDB I can’t recommend just one thing, but ScyllaDB is designed to run almost on autopilot. Rarely is there a need to tune any aspect of the ScyllaDB cluster. But if I had to pick one thing, it would be “proper NoSQL data modeling.” I have seen many teams struggle with performance because they had a poor data model. After spending some time with them and helping them fix their data model mistakes, their ScyllaDB cluster ran smoothly with the promised single-digit P99 latencies. I recommend everyone to join ScyllaDB University (it’s free) and take the beginner and advanced data modeling courses.ScyllaDB Operator 1.21 Release — with Oracle Kubernetes Engine (OKE) Support
Introducing Oracle Kubernetes Engine support, stronger TLS, and a lighter dependency footprint ScyllaDB Operator 1.21.0 is now available. For background, ScyllaDB Operator is an open-source project that helps you run ScyllaDB on Kubernetes. It lets you manage ScyllaDB clusters deployed to Kubernetes and automate tasks related to operating a ScyllaDB cluster (e.g., installation, vertical and horizontal scaling, as well as rolling upgrades). ScyllaDB Operator 1.21 expands cloud platform support with OKE, adds ECDSA as an alternative key type for TLS certificates, and removes a hard dependency on Prometheus Operator. Oracle Kubernetes Engine (OKE) support ScyllaDB Operator 1.21 adds Oracle Container Engine for Kubernetes (OKE) as a supported platform. The new OKE support comes with comprehensive documentation covering the entire workflow , from provisioning the underlying OCI infrastructure (VCN, subnets, gateways, and node pools with Dense I/O shapes and local NVMe storage) to deploying a 3-node ScyllaDB cluster spread across fault domains. An automated setup script is also provided for one-command infrastructure provisioning. To get started with ScyllaDB on OKE, see the Set up an OKE cluster for ScyllaDB infrastructure guide and the OKE reference deployment. ECDSA support for TLS certificates ScyllaDB Operator manages TLS certificates internally for securing client-to-node communication. Until now, only RSA keys were supported for certificate generation. ScyllaDB Operator 1.21 adds elliptic curve cryptography (ECDSA) as an alternative key type. This allows smaller key sizes and faster cryptographic operations with strong security. You can opt in to ECDSA by setting the –crypto-key-type=ECDSA flag on the operator, with the curve bit-size configurable via –crypto-ecdsa-key-size (defaulting to P-384). RSA remains the default key type. The RSA key size is now configured with a dedicated –crypto-rsa-key-size flag; the previous –crypto-key-size flag is deprecated and remains accepted as an alias. Prometheus Operator is now an optional dependency Previously, ScyllaDB Operator required Prometheus Operator CRDs (monitoring.coreos.com/v1) to be installed in the cluster, even if you did not intend to use ScyllaDBMonitoring. Missing CRDs would result in error logs at startup. With ScyllaDB Operator 1.21, Prometheus Operator becomes a purely optional dependency. The operator auto-detects whether the CRDs are present at startup using Kubernetes API discovery. When they are absent, the ScyllaDBMonitoring controller is not started and no error logs are emitted. If you install Prometheus Operator after the ScyllaDB Operator is already running, restart the operator to pick up the new CRDs. Refer to the monitoring setup guide for details.{kind=link}
Dear cqlsh: Your dependencies were killing us (P.S. We rewrote you in Rust)
A story of rewriting cqlsh in Rust…with Claude Code and a lot of planning Dearcqlsh, I vouched for
you. I told the team you were fine. I forked you, catered to you,
vendored your dependencies and your dependencies’ dependencies. I
patched things upstream that I knew you would never merge. I pinned
your Python, re-pinned it after the OS upgraded, and
explained to people (with a straight face) why that was totally
normal and not a problem at all. I wrote you twice already. You
never wrote back. I’m not even mad. I get it: you’re busy. 30+ CLI
flags, 25 CQL types, a COPY engine with enough options to fill a
man page…You’ve got a lot going on. But I found someone faster,
someone who compiles to a static binary without a runtime, without
vendoring. They don’t make me think about “which
Python are we using today?” They just…work. I hope you
understand. Yours (for now), Israel This is the story of cqlsh-rs – a ground-up
Rust rewrite of the Python
cqlsh, the interactive CQL shell used daily by
everyone working with Cassandra and ScyllaDB. It’s also a story
about what happens when you take the lessons from one AI-assisted
project and apply them to another project. Why bother rewriting?
Because packaging is a nightmare. ScyllaDB ships a relocatable
package, a self-contained bundle with its own Python
runtime baked in. The system Python can change,
upgrade, or disappear entirely, and ScyllaDB’s startup scripts and
cqlsh keep working because they’re running against a
known, pinned Python version inside the bundle. Except
cqlsh has to live inside that bundle. And
cqlsh is a Python tool. It has
dependencies, those dependencies’ dependencies have dependencies,
and they all need to be vendored in alongside the bundled
Python. Every time cqlsh or one of its
dependencies needs updating (a bug fix, a new Cassandra protocol
version, a security patch), you need to update the bundle, test the
bundle, and ship the bundle. And if something conflicts or breaks
inside that carefully pinned environment, it’s your problem to
untangle. A static Rust binary sidesteps all of this.
You compile once per target, you get a single file with zero
runtime dependencies, and you ship it. Done. The second pain point
is COPY TO/FROM, cqlsh‘s built-in feature
for bulk-exporting and importing table data to CSV. It’s one of the
most-used features, and it’s been carrying around a long list of
bugs for years. It does have parallel workers (threads and
processes), but the machinery is complicated, fragile, and
notoriously hard to test. The bug list reflects that. Both of these
are solvable in Rust. So, the question became: is now
the time to actually solve them? It all started with a BIG plan (to
the tune of The Big Bang Theory) In a previous
post, I wrote about using GitHub Copilot to bring a 4-year-old
Python idea (coodie, a Pydantic ODM for
Cassandra) back to life. That project was relatively contained:
give the AI a concept, come back to a working implementation. Fire
and forget it, more or less. cqlsh-rs is a different
category of project. The original Python
cqlsh has been around for over a decade. It has
hundreds of CLI flags, a compatibility matrix that spans multiple
database versions, a COPY engine with 30+ options per direction,
tab completion that must be schema-aware, and a type system
covering 25+ CQL types with specific formatting rules. Shipping
something that “mostly works” is not good enough if people are
going to actually switch to it. Every muscle-memory command has to
work the same way. So before writing a single line of
Rust, I started with a plan. That plan started as one
document. It grew, then it became a master design document plus
sub-plans. By the time the architecture settled, there were 19
sub-plans (SP01 through SP19) covering everything from the CLI
argument parser to the CQL type formatter to the COPY engine to a
future --ai-help flag for offline CQL error
diagnostics. Here’s what the roadmap looked like near the start:
5
out of 108 tasks. 0.4 tasks per day. The footer on that SVG read:
“Approximately 8.9 months remaining… just like Windows
said.” Reader, it did not take 8.9 months. “Wait, why is there
a skill for that?” I started in Claude web, but not because that’s
my comfort zone. With Copilot, I liked the browser because it made
the conversation visible to the team, a kind of shared thinking
space. I had the same instinct here. This way, design
conversations, architecture decisions, trade-off explorations, etc
all happened in the browser before a single file was created.
Questions like What driver to use? How to structure the CLI
argument parsing? Should we write a hand-rolled CQL parser or keep
it simple with a line-buffer approach? are genuinely better
answered in conversation than in code. The master plan came
together there. So did the first sub-plans and the initial CI
skeleton. Then I started exploring Claude Code, the CLI. Somewhere
around phase 2, I closed that browser tab once and for all. One
reason is the feedback loop: you’re in the same environment as the
code, so 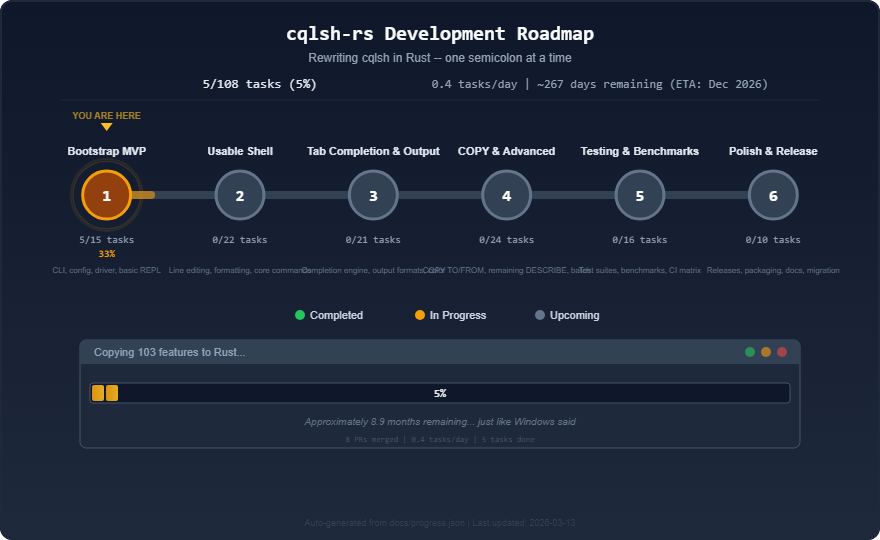{kind=link}
cargo test runs immediately after a change,
failures surface in context, and the next prompt can reference the
actual output. Another reason is just familiarity: the more you use
it, the more you learn to point it at exactly the right problem.
Skills: write your conventions once, use them forever The skills
library was also critical for this project:
/rust-testing – What to test at the unit layer vs. the
integration layer, how to use assert_cmd for CLI
tests, when to reach for insta snapshots
/rust-clippy – Run Clippy with strict
settings and fix everything it complains about
/rust-error-handling – Idiomatic error handling
patterns for this codebase /development-process – The
full loop: review the relevant sub-plan, design tests first,
implement, run tests, update the plan, commit I carried the pattern
directly from coodie. The specific skills are
different (Python vs. Rust), but the idea
is the same. Each skill you write makes every subsequent feature
cheaper to build. Living documents (or, an outdated plan is worse
than no plan) The 19 sub-plans are living documents that are
updated when decisions are made (vs written upfront and then
abandoned, like most docs). When a design decision changes
mid-implementation, the plan changes too. When a task is done, the
checkbox gets ticked. When a new edge case surfaces, it gets added.
This matters more than it might seem. An outdated plan is worse
than no plan because the AI will follow it faithfully…in the wrong
direction. What’s in the box Nothing terribly exotic; there’s: Rust
with Tokio for async. The scylla crate
for the database driver. rustyline for the REPL
and line editing. comfy-table and
owo-colors
for output formatting. testcontainers-rs
for spinning up real Cassandra instances in CI. While the stack
itself might not be exciting, the interesting part is what it takes
to get every CQL type to format exactly like the
Python implementation – right down to float
precision and frozen collection syntax. That’s where
most of the compatibility work lives. Where are we now? Here’s the
same roadmap today:
Phases 1 through 3 are done. The shell works: you can… Connect Run
queries Get formatted output with colors and pagination
Tab-complete keyspace and table names Run 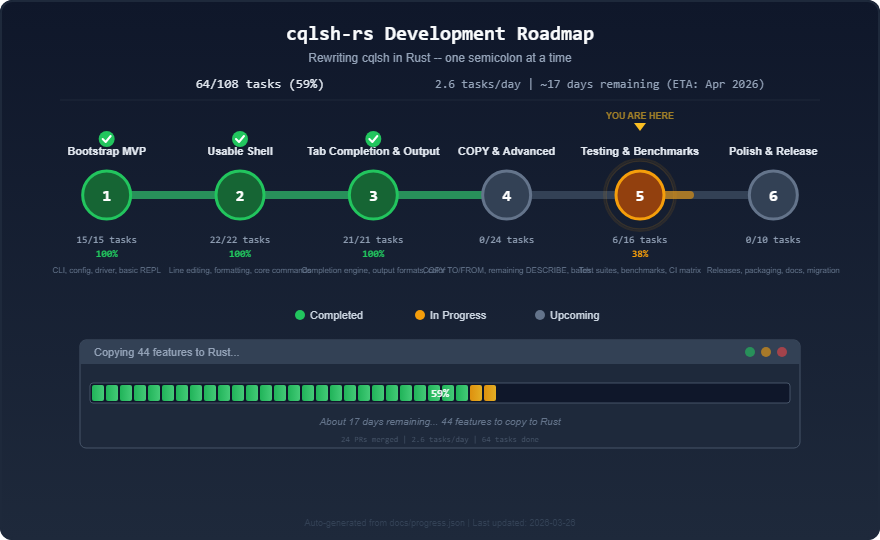{kind=link}
DESCRIBE on
anything Use SOURCE to execute a file Phase 4 –
COPY TO/FROM – is implemented. Phase 5 (testing) is in
progress, with 327 tests and counting. Takeaways Planning
pays (but living documents are a nice touch). A static
plan written at the start and never touched again is a liability. A
plan that gets updated as decisions are made is an asset – and the
primary reason Claude can work effectively across multiple sessions
on a project this size. Skills compound. A good
amount of work is required to find the right skill for the task and
adapt it to the project: the conventions, the patterns, the “this
is how we do it here” info. But once that’s written down, it
becomes easier to implement every feature. The workflow is
never done. The pace of this space is genuinely
disorienting. We now regularly use tools that didn’t even exist six
months ago. This means that what works today might not work in a
month. It’s still writing code, just differently.
(I have a bit of trouble using the word “engineering” here.) Claude
doesn’t replace judgment on architecture, on what actually matters
to users, on “is this the right trade-off?” It removes the friction
between having a clear idea of what you want and that thing
existing. Whether that makes it better or worse probably depends on
the day. Lessons from one project carry over to the
next. The skills pattern from coodie was
carried into cqlsh-rs with a different language and a
different domain. You can start from what you already learned, and
the AI follows the same process docs that you wrote last time.
Things to look forward to One idea that popped up during this: an
--ai-help flag that embeds a small local model to give
offline diagnostics when your CQL query fails. In other words,
building an AI-assisted tool with an AI assistant that will assist
with AI-assisted queries. I’m going to stop thinking about that too
hard. 😉 For the model routing, we’ll probably use
LiteLLM. I heard it’s become quite popular lately. I
had fun. Claude had fun too, probably. I didn’t ask. {kind=link}