Apache Cassandra® 6 Accord transactions: What you need to know
There have always been architectural trade-offs when considering a distributed database like Apache Cassandra versus a relational database. Cassandra excels at linear horizontal scalability, multi-region replication, and fault-tolerant uptime that relational systems couldn’t match. This comes at the expense of general-purpose ACID (Atomicity, Consistency, Isolation, Durability) transactions which allows the ability to express complex, multi-row operations with guaranteed consistency.
With Cassandra 6 on its way to general availability status (and an alpha already released), we’re approaching a turning point where we can revisit whether these trade-offs will still exist. The latest version delivers general-purpose ACID transactions through a new protocol called Accord. With Cassandra 6, those transactional guarantees will be native, without compromising Cassandra’s operational model or availability.
TransactionsIn database parlance, a transaction says, “These operations belong together. They must all be applied, or none of them.” The classic example is a bank transfer. When you move money from one account to another, two things must happen: a debit and a credit. If the debit succeeds but the credit fails, money has disappeared. A transaction prevents this issue by guaranteeing the two operations are atomic, meaning they succeed or fail as a unit; combined with isolation, no other process can see an immediate or half-finished state.
Experiences like these depend on transactional guarantees at the data layer, which rely on ACID semantics, particularly atomicity and isolation, to prevent inconsistent intermediate states.
For most developers who have worked with relational databases, transactions are so fundamental they’re almost invisible. For Cassandra users, comparable guarantees across multiple partitions or tables historically required significant application-level coordination or weren’t natively supported.
Coordination at scale is fundamentally hardBecause Cassandra is designed to deal with data replication and scaling, coordinating atomic changes across multiple nodes is inherently challenging (e.g., decrement a balance here, increment one there). All participating replicas must agree on an order of operations. Distributed consensus protocols exist to solve exactly this, but prior approaches came with trade-offs.
Raft and Zab are examples of protocols that use leaders, which is not suitable for Cassandra since nodes are treated equally.
More information about prior solutions can be found in more details in CEP-15, but generally, leader-based approaches pose issues at scale.
The Accord protocolThe Accord protocol, proposed in CEP-15, is built to achieve fast, general-purpose distributed transactions that remain stable under the same failure conditions Cassandra already tolerates— with no elected leaders.
How it orders transactionsAccord is leaderless so any node can coordinate any transaction. Transactions are assigned unique timestamps using hybrid logical clocks, where each node appends its own unique ID to its clock value to ensure global uniqueness across the cluster. Conflicting transactions execute in timestamp order across all replicas. Under normal conditions, a transaction reaches consensus in a single round trip.
The reorder bufferThe challenge with timestamp-based ordering in a geo-distributed system is that two transactions started concurrently from different regions might arrive at replicas in different orders, breaking fast-path consensus. Accord solves this by having replicas buffer incoming transactions. The wait time is precisely bounded to be just long enough to account for clock differences between nodes and network latency, and no longer. This guarantees that replicas always process transactions in the correct order without needing extra message rounds.
Fast-path electoratesWhen replicas fail, other leaderless protocols fall back to slower, more expensive message patterns. Accord avoids this by dynamically adjusting which replicas participate in fast-path decisions as failures occur. The result is that Accord maintains fast-path availability under failure, avoiding the degradation to slower message patterns that other leaderless protocols experience.
The net effect: strict serializable isolation across multiple partitions and tables, in a single round trip, with no leaders, and preserving performance characteristics under the same minority‑failure conditions that Cassandra is designed to tolerate.
New CQL syntax to support transactionsThe most visible change for developers is new CQL syntax.
Transactions in Cassandra 6 are wrapped in BEGIN
TRANSACTION and COMMIT TRANSACTION blocks,
similar to SQL syntax.
Let’s examine a flight booking transaction that must simultaneously reserve a seat and deduct loyalty miles from two separate tables. Note: Cassandra 6 is pre-release. Syntax shown reflects the current alpha and may evolve before general availability.
BEGIN TRANSACTION LET seat = (SELECT available FROM flight_seats WHERE flight_id = 'ZZ101' AND seat_number = '14C'); LET miles = (SELECT balance FROM loyalty_accounts WHERE member_id = 'M-7823'); IF seat.available = true AND miles.balance >= 25000 THEN UPDATE flight_seats SET available = false, booked_by = 'M-7823' WHERE flight_id = 'ZZ101' AND seat_number = '14C'; UPDATE loyalty_accounts SET balance = miles.balance - 25000 WHERE member_id = 'M-7823'; END IF COMMIT TRANSACTION ;
Everything between BEGIN TRANSACTION and
COMMIT TRANSACTION executes atomically with strict
serializable isolation from the perspective of all other concurrent
transactions. The LET clause reads current values from
the database and binds them to variables. The IF block uses those
values to guard the writes. If the seat is already taken or the
member doesn’t have enough miles, nothing happens. Both updates
either apply together or not at all, across two different tables
and two different partition keys.
This is logic that previously had to live in the application, complete with retry handling, race condition guards, and compensating operations if something failed halfway through. Now it lives in the database.
Enabling Accord in Cassandra 6: The CMS dependencyWe can’t talk about Accord without discussing Cluster Metadata Service (CMS). Before Accord transactions are functional, Cluster Metadata Service (CMS), introduced alongside Accord as CEP-21, must be enabled. For teams upgrading from Cassandra 5, this is the most significant operational change in the release.
CMS is required. Accord needs every replica to have the same authoritative view of cluster topology showing which nodes own which data, and which replicas participate in a given transaction. Before Cassandra 6, this information was propagated via the eventually consistent Gossip Protocol. This is suitable for normal reads and writes, but Accord’s correctness depends on knowing precisely who the transaction participants are before committing. CMS replaces Gossip-based metadata propagation with a distributed, linearized transaction log, giving all nodes a consistent view of cluster state. Without it, Accord’s guarantees don’t hold.
Upgrading from Cassandra 5 to 6—plan carefullyThe upgrade cannot begin until every node in the cluster is running Cassandra 6. CMS initialization requires full cluster agreement; no mixed-version clusters are supported. Before upgrading, disable any automation that could trigger schema changes, node bootstrapping, decommissions, or replacements. These operations are blocked during the upgrade window, and if they fire on an older node before CMS is initialized, the migration can fail in ways that require manual intervention to recover.
Once all nodes are upgraded, run nodetool cms
initialize on one node to activate CMS. This creates the
service with a single member, which is enough to unblock metadata
operations but is not suitable for production. Follow up
immediately with nodetool cms reconfigure to add more
members. CMS uses Paxos internally and requires a minimum of three
nodes for a viable quorum, with more recommended for production
depending on cluster size.
Important: CMS initialization is not easily reversible. Plan the upgrade window accordingly and treat it as a one-way operational step.
On a fresh Cassandra 6 cluster that wasn’t migrated from a previous version, CMS is automatically enabled. First, one node is designated as the initial CMS member. From there, CMS membership scales automatically based on cluster size, with the service adding members as the cluster grows without requiring manual intervention.
Of course, for Instaclustr users, our platform and techops team will take care of most of this for you and walk you through any requirements on your side when the time comes to upgrade.
Coexistence with Lightweight Transactions (LWT)Existing LWT syntax (IF NOT EXISTS, IF
EXISTS, conditional UPDATE/INSERT statements)
continues to work and fundamentally differs from Accord
transactions as LWT is scoped to a single partition and is
extremely limited. Accord doesn’t replace or break existing
applications. Using BEGIN TRANSACTION/END TRANSACTION
is how developers opt into the broader cross-partition
guarantees.
Every prior approach to distributed transactions required accepting one of three constraints: a global leader (single point of failure, WAN latency penalty), limited to single-partition scope (LWT), or degraded performance under failure (prior leaderless protocols). The Accord paper’s central claim is that these constraints are not fundamental. They are artifacts of specific protocol design choices.
By combining flexible fast-path electorates with a timestamp reorder buffer on top of a leaderless execution model, Accord achieves:
- True cross-partition atomicity across multiple tables and partition keys
- Strict serializable isolation with formally proven correctness
- Single round-trip latency under normal operating conditions
- Failure‑tolerant steady‑state performance, avoiding the systematic degradation seen in earlier leaderless protocols
- No elected leaders, consistent with Cassandra’s existing operational model
This opens workloads that were previously natively incompatible with Cassandra: financial transaction processing, distributed inventory reservation, multi-step workflow coordination, and any application where ‘commit these changes together or not at all’ is a strict correctness requirement.
Looking aheadThough the Accord protocol is still maturing, the fundamental capability is finally here. We now have general-purpose, leaderless, multi-partition ACID transactions natively in Apache Cassandra.
The historically difficult problem of achieving strict serializable isolation in a geo-distributed system without compromising fault tolerance now has a proven, working answer.
For Cassandra users, this raises an exciting question: which workloads have you been routing to relational databases specifically because they needed transactional guarantees? It is time to reevaluate.
Stay tuned for a preview release of Cassandra 6 on the Instaclustr Platform and get ready to experience the power of ACID transactions on Cassandra for yourself!
The post Apache Cassandra® 6 Accord transactions: What you need to know appeared first on Instaclustr.
Instaclustr product update: March 2026
Here’s a roundup of the latest features and updates that we’ve recently released.
If you have any particular feature requests or enhancement ideas that you would like to see, please get in touch with us.
Major announcements Introducing AI Cluster Health: Smarter monitoring made simpleTurn complex metrics into clear, actionable insights with AI-powered health indicators—now available in the NetApp Instaclustr console. The new AI Cluster Health page simplifies cluster monitoring, making it easy to understand your cluster’s state at a glance without requiring deep technical expertise. This AI-driven analysis reviews recent metrics, highlights key indicators, explains their impact, and assigns an easy traffic-light health score for a quick status overview.
NetApp introduces Apache Kafka® Tiered Storage support on GCP in public previewTiered Storage is now available in public review for Instaclustr for Apache Kafka on Google Cloud Platform. This feature enables customers to optimize storage costs and improve scalability by offloading older Kafka log segments from local disk to Google Cloud Storage (GCS), while keeping active data local for fast access. Kafka clients continue to consume data seamlessly with no changes required, allowing teams to reduce infrastructure costs, simplify cluster scaling, and extend retention periods for analytics or compliance.
Other significant changes Apache Cassandra®- Released Apache Cassandra 4.0.19 and 5.0.6 into general availability on the NetApp Instaclustr Managed Platform, giving customers access to the latest stability, performance, and security improvements.
- Multi–data center Apache Cassandra clusters can now be provisioned across public and private networks via the Instaclustr Console, API, and Terraform provider, enabling customers to provision multi-DC clusters from day one.
- Single CA feature is now available for Apache Cassandra clusters. See Single CA for more details.
- GCP n4 machine types are now supported for Apache Cassandra in the available regions.
- Apache Kafka and Kafka Connect 4.1.1 are now generally available.
- Added Client Telemetry feature support for Kafka in private preview.
- Single CA feature is now available for Apache Kafka clusters. See Single CA for more details.
- ClickHouse 25.8.11 has been added to our managed platform in General Availability.
- Enabled ClickHouse
system.session_logtable that plays a key role in tracking session lifecycle and auditing user activities for enhanced session monitoring. This helps you with troubleshooting client-side connectivity issues and provides insights into failed connections.
- OpenSearch 2.19.4 and 3.3.2 have been released to general availability.
- Added support for the OpenSearch Assistant feature in OpenSearch Dashboards for clusters with Dashboards and AI Search enabled.
- PostgreSQL version 18.1 has now been released to general availability, alongside PostgreSQL version 17.7.
- PgBouncer version 1.25.0 has now been released to general availability.
- Added self-service Tags Management feature—allowing users to add, edit, or delete tags for their clusters directly through the Instaclustr console, APIs, or Terraform provider for RIYOA deployments
- Added new region Germany West Central for Azure
- Following the private preview release, Kafka’s Client Telemetry feature is progressing toward general availability soon. Read more here.
- We plan to extend the current ClickHouse integration with FSxN data sources by adding support for deployments across different VPCs, enabling broader enterprise lakehouse architectures.
- Apache Iceberg and Delta Lake integration are planned to soon be available for ClickHouse on the NetApp Instaclustr Platform, giving you a practical way to run analytics on open table formats while keeping control of your existing data platforms.
- We plan to soon introduce fully integrated AWS PrivateLink as a ClickHouse Add-On for secure and seamless connectivity with ClickHouse.
- We’re aiming to launch PostgreSQL integrated with FSx for NetApp ONTAP (FSxN) along with NVMe support into general availability soon. This enhancement is designed to combine enterprise-grade PostgreSQL with FSxN’s scalable, cost-efficient storage, enabling customers to optimize infrastructure costs while improving performance and flexibility. NVMe support is designed to deliver up to 20% greater throughput vs NFS.
- An AI Search plugin for OpenSearch is being released to GA (currently in public preview) to enhance search experiences using AI‑powered techniques such as semantic, hybrid, and conversational search, enabling more relevant, context‑aware results and unlocking new use cases including retrieval‑augmented generation (RAG) and AI‑driven chatbots.
- Following the public preview release, Zero Inbound Access is progressing to General Availability, designed to deliver the most secure management connectivity by eliminating inbound internet exposure and removing the need for any routable public IP addresses, including bastion or gateway instances.
- Explore how to freeze your streaming data for long-term
analytical queries in the future with our two-part blog series:
Freezing streaming data into Apache Iceberg
 —Part 1: Using Apache Kafka®Connect Iceberg Sink Connector
introduces Apache Iceberg and demonstrates streaming Kafka data
using the Apache Kafka Connect Iceberg Sink Connector and
Freezing streaming data into Apache Iceberg—Part 2: Using Iceberg Topics examines the experimental
approach of using Kafka Tiered Storage and Iceberg Topics, where
non‑active Kafka segments are copied to remote storage while
remaining transparently readable by Kafka clients.
—Part 1: Using Apache Kafka®Connect Iceberg Sink Connector
introduces Apache Iceberg and demonstrates streaming Kafka data
using the Apache Kafka Connect Iceberg Sink Connector and
Freezing streaming data into Apache Iceberg—Part 2: Using Iceberg Topics examines the experimental
approach of using Kafka Tiered Storage and Iceberg Topics, where
non‑active Kafka segments are copied to remote storage while
remaining transparently readable by Kafka clients. - Modern search applications go beyond simple keyword matching, requiring a deep understanding of user intent and context to deliver relevant, meaningful results. From keywords to concepts: How OpenSearch® AI search outperforms traditional search explores how semantic and hybrid search methods in OpenSearch AI search compare to traditional keyword search, and how you can use these capabilities for more relevant results.
- Generative AI and Large Language Models (LLMs) are booming, and they’ve put a spotlight on a crucial technology: vector search. Many applications today demand high throughput, low latency, and constant availability for retrieving information. Slow vector search can become a significant bottleneck, delaying responses and degrading the user experience. Our two-part series blogs Vector search benchmarking: Setting up embeddings, insertion, and retrieval with PostgreSQL® and Vector search benchmarking: Embeddings, insertion, and searching documents with ClickHouse® and Apache Cassandra® explore hands-on findings from our benchmarking projects, the role of databases in vector search, how to set up vector search for embeddings, insertion, and retrieval, and practical strategies for building faster, more efficient semantic search systems.
If you have any questions or need further assistance with these enhancements to the Instaclustr Managed Platform, please contact us.
SAFE HARBOR STATEMENT: Any unreleased services or features referenced in this blog are not currently available and may not be made generally available on time or at all, as may be determined in NetApp’s sole discretion. Any such referenced services or features do not represent promises to deliver, commitments, or obligations of NetApp and may not be incorporated into any contract. Customers should make their purchase decisions based upon services and features that are currently generally available.
The post Instaclustr product update: March 2026 appeared first on Instaclustr.
Claude Code Marketplace Now Available
Claude Code has become an indispensable part of my daily workflow. I use it for everything from writing code to debugging production issues. But while Claude is incredibly capable out of the box, there are areas where injecting specialized domain knowledge makes it dramatically more useful.
That’s why I built a plugin marketplace. Yesterday I released rustyrazorblade/skills, a collection of Claude Code plugins that extend Claude with expert-level knowledge in specific domains. The first plugin is something I’ve been talking about doing for a while: a Cassandra expert.
Apache Cassandra® 5.0: Improving performance with Unified Compaction Strategy
IntroductionUnified Compaction Strategy (UCS), introduced in Apache Cassandra 5.0, is a versatile compaction framework that not only unifies the benefits of Size-Tiered (STCS) and Leveled (LCS) Compaction Strategies, but also introduces new capabilities like shard parallelism, density-aware SSTable organization, and safer incremental compaction, all of which deliver more predictable performance at scale. By utilizing a flexible scaling model, UCS allows operators to tune compaction behavior to match evolving workloads, spanning from write-heavy to read-heavy, without requiring disruptive strategy migrations in most cases.
In the past, operators had to choose between rigid strategies and accept significant trade-offs. UCS changes this paradigm, allowing the system to efficiently adapt to changing workloads with tuneable configurations that can be altered mid-flight and even applied differently across different compaction levels based on data density.
Why compaction mattersCompaction is the critical process that determines a cluster’s long-term health and cost-efficiency. When executed correctly, it produces denser nodes with highly organized SSTables, allowing each server to store more data without sacrificing speed. This efficiency translates to a smaller infrastructure footprint, which can lower cloud costs and resource usage.
Conversely, inefficient compaction is a primary driver of performance degradation. Poorly managed SSTables lead to fragmented data, forcing the system to work harder for every request. This overhead consumes excessive CPU and I/O, often forcing teams to try adding more nodes (horizontal scale) just to keep up with background maintenance noise.
Key concepts and terminologyTo understand how UCS optimizes a cluster, it is necessary to understand the fundamental trade-offs it balances:
- Read amplification: Occurs when the database must consult multiple SSTables to answer a single query. High read amplification acts as a “latency tax,” forcing extra I/O to reconcile data fragments.
- Write amplification: A metric that quantifies the overhead of background processes (such as compactions). It represents the ratio between total data written to disk and the amount of data originally sent by an application. High write amplification wears out SSDs and steals throughput.
- Space amplification: The ratio of disk space used to the actual size of the “live” data. It tracks data such as tombstones or overwritten rows that haven’t been purged yet.
- Fan factor: The “growth dial” for the cluster data hierarchy. It defines how many files of a similar size must accumulate before they are merged into a larger tier.
- Sharding: UCS splits data into smaller, independent token ranges (shards), allowing the system to run multiple compactions in parallel across CPU cores.
UCS provides baseline architectural improvements that were not available in older strategies:
Improved compaction parallelismOlder strategies often got stuck on a single thread during large merges. UCS sharding allows a server to use its full processing power. This significantly reduces the likelihood of compaction storms and keeps tail latencies (p99) predictable.
Reduced disk space amplificationBecause UCS operates on smaller shards, it doesn’t need to double the entire disk space of a node to perform a major merge. This greatly reduces the risk of nodes from running out of space during heavy maintenance cycles.
Density-based SSTable organizationUCS measures SSTables by density (token range coverage). This mitigates the huge SSTable problem where a single massive file becomes too large to compact, hindering read performance indefinitely.
Scaling parameterThe scaling parameter (denoted as W) is a configurable setting that determines the size ratio between compaction tiers. It helps balance write amplification and read performance by controlling how much data is rewritten during compaction operations. A lower scaling parameter value results in more frequent, smaller compactions, whereas a higher value leads to larger compaction groups.
The strategy engine: tuning and parametersUCS acts as a strategy engine by adjusting the scaling parameter (W), allowing UCS to mimic, or outperform, its predecessors STCS and LCS.
At a high level, the scaling parameter influences the effective fan-out behavior at each compaction level. Tiered-style settings such as T4 allow more SSTables to accumulate before merging, favoring write efficiency, while leveled-style settings such as L10 keep SSTables more tightly organized, reducing read amplification at the cost of additional background work.
The numbers below are illustrative and not prescriptive:
UCS configuration guide Workload type Strategy target Scaling (W) Primary benefit Heavy writes / IoT STCS (Tiered) Negative (e.g., -4) Lowest read amplification Heavy reads LCS (Leveled) Positive (e.g., 10) Lowest write amplification Balanced Hybrid Zero (0) Balanced performance for general apps Practical exampleUCS allows operators to mix behaviors across the data lifecycle.
'scaling_parameters': 'T4, T4, L10'
Note that scaling_parameters takes a string format that can accommodate parameters for per-level tuning.
This example instructs a cluster: “Use tiered compaction for the first two levels to keep up with the high write volume, but once data reaches the third level, reorganize it into a leveled structure so reads stay fast.”
Here’s a fuller, illustrative example of how one might structure their CQL to change the compaction strategy.
ALTER TABLE keyspace_name.table_name WITH compaction = { 'class': 'UnifiedCompactionStrategy', 'scaling_parameters': 'T4,T4,L10' };
Operational evolution: moving beyond major compactions
In older strategies and in Apache Cassandra versions prior to 5.0, operators often felt forced to run a major compaction to reclaim disk space or fix performance. This was a critical event that could impact a node’s I/O for extended periods of time and required substantial free disk space to complete.
Because UCS is density-aware and sharded, it effectively performs compactions constantly and granularly so major compactions are rarely needed. It identifies overlapping data within specific token ranges (shards) and cleans them up incrementally. Operators no longer must choose between a fragmented disk and a risky, resource-heavy manual compaction; UCS keeps data density more uniform across the cluster over time.
The migration advantage: “in-place” adoptionOne of the key performance features of a UCS migration is in-place adoption, meaning that when a table is switched to UCS, it does not immediately force a massive data rewrite. Instead, it looks at the existing SSTables, calculates their density, and maps them into its new sharding structure.
This allows for moving from STCS or LCS to UCS with significantly less I/O overhead than any other strategy change.
ConclusionUCS is an operational shift toward simplicity and predictability. By removing the need to choose between compaction trade-offs, UCS allows organizations to scale with confidence. Whether handling a massive influx of IoT data or serving high-speed user profiles, UCS helps clusters remain performant, cost-effective, and ready for the future.
On a newly deployed NetApp Instaclustr Apache Cassandra 5 cluster, UCS is already the default strategy (while Apache Cassandra 5.0 has STCS set as the default).
Ready to experience this new level of Cassandra performance for yourself? Try it with a free 30-day trial today!
The post Apache Cassandra® 5.0: Improving performance with Unified Compaction Strategy appeared first on Instaclustr.
Exploring the key features of Cassandra® 5.0
Apache Cassandra has become one of the most broadly adopted distributed databases for large-scale, highly available applications since its launch as an open source project in 2008. The 5.0 release in September 2024 represents the most substantial advancement to the project since 4.0 released in July 2021. Multiple customers (and our own internal Cassandra use case) have now been happily running on Cassandra 5 for up to 12 months so we thought the time was right to explore the key features they are leveraging to power their modern applications.
An overview of new features in Apache Cassandra 5.0Apache Cassandra 5.0 introduces core capabilities aimed at AI-driven systems, low-latency analytical workloads, and environments that blend operational and analytical processing.
Highlights include:
- The new vector data type and an Approximate Nearest Neighbor (ANN) index based on Hierarchical Navigable Small World (HNSW), which is integrated into the Storage-Attached Index (SAI) architecture
- Trie-based memtables and the Big Trie-Index (BTI) SSTable format, delivering better memory efficiency and more consistent write performance
- The Unified Compaction Strategy, a tunable density-based approach that can align with leveled or tiered compaction patterns.
Additional enhancements include expanded mathematical CQL functions, dynamic data masking, and experimental support for Java 17.
At NetApp, Apache Cassandra 5.0 is fully supported, and we are actively assisting customers as they transition from 4.x.
A deeper look at Cassandra 5.0’s key features Storage–Attached Indexes (SAI)Storage–Attached Indexes bring a modern, storage-integrated approach to secondary indexing in Apache Cassandra, resolving many of the scalability and maintenance challenges associated with earlier index implementations. Legacy Secondary Indexes (2i) and SASI remain available, but SAI offers a more robust and predictable indexing model for a broad range of production workloads.
SAI operates per-SSTable, allowing queries to be indexed locally versus the cluster-wide coordination required of other strategies. This model supports diverse CQL data types, enables efficient numeric and text range filters, and provides more consistent performance characteristics than 2i or SASI. The same storage-attached foundation is also used for Cassandra 5’s vector indexing mechanism, allowing ANN search to operate within the same storage and query framework.
SAI supports combining filters across multiple indexed columns and works seamlessly with token-aware routing to reduce unnecessary coordinator work. Public evaluations and community testing have shown faster index builds, more predictable read paths, and improved disk utilization compared with previous index formats.
Operationally, SAI functions as part of the storage engine itself: indexes are defined using standard CQL statements and are maintained automatically during flush and compaction, with no cluster-wide rebuilds required. This provides more flexible query options and can simplify application designs that previously relied on manual denormalization or external indexing systems.
Native Vector Search capabilitiesApache Cassandra 5.0 introduces native support for high-dimensional vector embeddings through the new vector data type. Embeddings represent semantic information in numerical form, enabling similarity search to be performed directly within the database. The vector type is integrated with the database’s storage-attached index architecture, which uses HNSW graphs to efficiently support ANN search across cosine, Euclidean, and dot-product similarity metrics.
With vector search implemented at the storage layer, applications involving semantic matching, content discovery, and retrieval-oriented workflows while maintaining the system’s established scalability and fault-tolerance characteristics are supported.
After upgrading to 5.0, existing schemas can add vector columns and store embeddings through standard write operations. For example:
UPDATE products SET embedding = [0.1, 0.2, 0.3, 0.4, 0.5] WHERE id = <id>;
To create a new table with a vector type column:
CREATE TABLE items ( product_id UUID PRIMARY KEY, embedding VECTOR<FLOAT, 768> // 768 denotes dimensionality );
Because vector indexes are attached to SSTables, they participate automatically in the compaction and repair processes and do not require an external indexing system. ANN queries can be combined with regular CQL filters, allowing similarity searches and metadata conditions to be evaluated within a unified distributed query workflow. This brings vector retrieval into Apache Cassandra’s native consistency, replication, and storage model.
Unified Compaction Strategy (UCS)Unified Compaction Strategy in Apache Cassandra 5 included a density-aware approach to organizing SSTables that blends the strengths of Leveled Compaction Strategy (LCS) and Size Tiered Compaction Strategy (STCS). UCS aims to provide the predictable read amplification associated with LCS and the write efficiency of STCS, without many of the workload-specific drawbacks that previously made compaction selection difficult. Choosing an unsuitable compaction strategy in earlier releases could lead to operational complexity and long-term performance issues, which UCS is designed to mitigate.
UCS exposes a set of tunable parameters like density thresholds and per-level scaling that let operators adjust compaction behavior toward read-heavy, write-heavy, or time-series patterns. This flexibility also helps smooth the transition from existing strategies, as UCS can adopt and improve the current SSTable layout without requiring a full rewrite in most cases. The introduction of compaction shards further increases parallelism and reduces the impact of large compactions on cluster performance.
Although LCS and STCS remain available (and while STCS remains the default strategy in 5.0, UCS is the default strategy on newly deployed NetApp Instaclustr’s managed Apache Cassandra 5 clusters), UCS supports a broader range of workloads, reduces the operational burden of compaction tuning, and aligns well with other storage engine improvements in Apache Cassandra 5 such as trie-based SSTables and Storage-Attached Indexes.
Trie Memtables and Trie-Indexed SSTablesTrie Memtables and Trie-indexed SSTables (Big Trie-Index, BTI) are significant storage engine enhancements released in Apache Cassandra 5. They are designed to reduce memory overhead, improve lookup performance, and increase flush efficiency. A trie data structure stores keys by shared prefixes instead of repeatedly storing full keys, which lowers object count and improves CPU cache locality compared with the legacy skip-list memtable structure. These benefits are particularly visible in high-ingestion, IoT, and time-series workloads.
Skip-list memtables store full keys for every entry, which can lead to large heap usage and increased garbage collection activity under heavy write loads. Trie Memtables substantially reduce this overhead by compacting key storage and avoiding pointer-heavy layouts. On disk, the BTI SSTable format replaces the older BIG index with a trie-based partition index that removes redundant key material and reduces the number of key comparisons needed during partition lookups.
Using Trie memtables requires enabling both the trie-based memtable implementation and the BTI SSTable format. Existing BIG SSTables are converted to BTI through normal compaction or by rebuilding data. On NetApp Instaclustr’s managed Apache Cassandra clusters Trie Memtables and BTI are enabled by default, but when upgrading major versions to 5.0, data must be converted from BIG to BTI first to utilize Trie structures.
Other new features Mathematical CQL functionsApache Cassandra 5.0 added a rich set of math functions allowing developers to perform computations directly within queries. This reduces data transfer overhead and reduces client-side post-processing, among many other benefits. From fundamental functions like ABS(), ROUND(), or SQRT() to more complex operations like SIN(), COS(), TAN(), these math functions are extensible to a multitude of domains from financial data, scientific measurements or spatial data.
Dynamic Data MaskingDynamic Data Masking (DDM) is a new feature to obscure sensitive
column-level data at query time or permanently attach the
functionality to a column so that the data always returns
obfuscated. Stored data values are not altered in this process, and
administrators can control access through role-based access control
(RBAC) to ensure only those with access can see the data while also
tuning the visibility of the obscured data. This feature helps with
adherence to data privacy regulations such as GDPR, HIPAA, and PCI
DSS without needing external redaction systems.
Apache Cassandra 5.0 packs a punch with game changing features that meet the needs of modern workloads and applications. Features like vector search capabilities and Storage Attached Indexes stand out as they will inevitably shape how data can be leveraged within the same database while maintaining speed, scale, and resilience.
When you deploy a managed cluster on NetApp Instaclustr’s Managed Platform, you get the benefits of all these amazing features without worrying about configuration and maintenance.
Ready to experience the power of Apache Cassandra 5.0 for yourself? Try it free for 30 days today!
The post Exploring the key features of Cassandra® 5.0 appeared first on Instaclustr.
Instaclustr product update: December 2025
Instaclustr product update: December 2025Here’s a roundup of the latest features and updates that we’ve recently released.
If you have any particular feature requests or enhancement ideas that you would like to see, please get in touch with us.
Major announcements OpenSearch®AI Search for OpenSearch®: Unlocking next-generation search
AI Search for OpenSearch, which is now available in Public Preview on the NetApp Instaclustr Managed Platform, is designed to bring semantic, hybrid, and multimodal search capabilities to OpenSearch deployments—turning them into an end-to-end AI-powered search solution within minutes. With built-in ML models, vector indexing, and streamlined ingestion pipelines, next-generation search can be enabled in minutes without adding operational complexity. This feature powers smarter, more relevant discovery experiences backed by AI—securely deployed across any cloud or on-premises environment.
ClickHouse®
FSx for NetApp ONTAP and Managed ClickHouse® integration is now
available
We’re excited to announce that NetApp has introduced seamless
integration between Amazon FSx for NetApp ONTAP and Instaclustr
Managed ClickHouse, to enable customers to build a truly hybrid
lakehouse architecture on AWS. This integration is designed to
deliver lightning-fast analytics without the need for complex data
movement, while leveraging FSx for ONTAP’s unified file and object
storage, tiered performance, and cost optimization. Customers can
now run zero-copy lakehouse analytics with ClickHouse directly on
FSx for ONTAP data—to simplify operations, accelerate
time-to-insight, and reduce total cost of ownership.
Instaclustr for PostgreSQL® on Amazon FSx for ONTAP: A new
era
We’re excited to announce the public preview of Instaclustr Managed
PostgreSQL integrated with Amazon FSx for NetApp ONTAP—combining
enterprise-grade storage with world-class open source database
management. This integration is designed to deliver higher IOPS,
lower latency, and advanced data management without increasing
instance size or adding costly hardware. Customers can now run
PostgreSQL clusters backed by FSx for ONTAP storage, leveraging
on-disk compression for cost savings and paving the way for
ONTAP-powered features, such as instant snapshot backups, instant
restores, and fast forking. These ONTAP-enabled features are
planned to unlock huge operational benefits and will be launched
with our GA release.
- Released Apache Cassandra 5.0.5 into general availability on the NetApp Instaclustr Managed Platform.
- Transitioned Apache Cassandra v4.1.8 to CLOSED lifecycle state; scheduled to reach End of Life (EOL) on December 20, 2025.
- Kafka on Azure now supports v5 generation nodes, available in General Availability.
- Instaclustr Managed Apache ZooKeeper has moved from General Availability to closed status.
- Kafka and Kafka Connect 3.1.2 and 3.5.1 are retired; 3.6.2, 3.7.1, 3.8.1 are in legacy support. Next set of lifecycle state changes for Kafka and Kafka Connect in end March 2026 will see all supported versions 3.8.1 and below marked End of Life.
- Karapace Rest Proxy and Schema Registry 3.15.0 are closed. Customers are advised to move to version 5.x.
- Kafka Rest Proxy 5.0.0 and Kafka Schema Registry 5.0.0, 5.0.4 have been moved to end of life. Affected customers have been contacted by Support to schedule a migration to a supported version as soon as possible.
- ClickHouse 25.3.6 has been added to our managed platform in General Availability.
- Kafka Table Engine integration with ClickHouse has added support to enable real-time data ingestion, streamline streaming analytics, and accelerate insights.
- New ClickHouse node sizes, powered by AWS m7g, r7i, and r7g instances, are now in Limited Availability for cluster creation.
- Cadence is now available to be provisioned with Cassandra 5.x, designed to deliver improved performance, enhanced scalability, and stronger security for mission-critical workflows.
- OpenSearch 2.19.3 and 3.2.0 have been released to General Availability.
- PostgreSQL AWS PrivateLink support has been added, enabling connectivity between VPCs using AWS PrivateLink.
- PostgreSQL version 18.0 has now been released to General Availability, alongside PostgreSQL version 16.10, 17.6.
- Added new PostgreSQL metrics for connect states and wait event types.
- PostgreSQL Load Balancer add-on is now available, providing a unified endpoint for cluster access, simplifying failover handling, and ensuring node health through regular checks.
- We’re working on enabling multi-datacenter (multi-DC) cluster provisioning via API and console, designed to make it easier to deploy clusters across regions with secure networking and reduced manual steps.
- We’re working on adding Kafka Tiered Storage for clusters running in GCP— designed to bring affordable, scalable retention, and instant access to historical data, to ensure flexibility and performance across clouds for enterprise Kafka users.
- We’re planning to extend our Managed ClickHouse to allow it to work with on-prem deployments.
- Following the success of our public preview, we’re preparing to launch PostgreSQL integrated with FSx for NetApp ONTAP (FSxN) into General Availability. This enhancement is designed to combine enterprise-grade PostgreSQL with FSxN’s scalable, cost-efficient storage, enabling customers to optimize infrastructure costs while improving performance and flexibility.
- As part of our ongoing advancements in AI for OpenSearch, we are planning to enable adding GPU nodes into OpenSearch clusters, aiming to enhance the performance and efficiency of machine learning and AI workloads.
- Self-service Tags Management feature—allowing users to add, edit, or delete tags for their clusters directly through the Instaclustr console, APIs, or Terraform provider for RIYOA deployments.
- Cadence Workflow, the open source orchestration engine created by Uber, has officially joined the Cloud Native Computing Foundation (CNCF) as a Sandbox project. This milestone ensures transparent governance, community-driven innovation, and a sustainable future for one of the most trusted workflow technologies in modern microservices and agentic AI architectures. Uber donates Cadence Workflow to CNCF: The next big leap for the open source project—read the full story and discover what’s next for Cadence.
- Upgrading ClickHouse® isn’t just about new features—it’s essential for security, performance, and long-term stability. In ClickHouse upgrade: Why staying updated matters, you’ll learn why skipping upgrades can lead to technical debt, missed optimizations, and security risks. Then, explore A guide to ClickHouse® upgrades and best practices for practical strategies, including when to choose LTS releases for mission-critical workloads and when stable releases make sense for fast-moving environments.
- Our latest blog, AI Search for OpenSearch®: Unlocking next-generation search, explains how this new solution enables smarter discovery experiences using built-in ML models, vector embeddings, and advanced search techniques—all fully managed on the NetApp Instaclustr Platform. Ready to explore the future of search? Read the full article and see how AI can transform your OpenSearch deployments.
If you have any questions or need further assistance with these enhancements to the Instaclustr Managed Platform, please contact us.
SAFE HARBOR STATEMENT: Any unreleased services or features referenced in this blog are not currently available and may not be made generally available on time or at all, as may be determined in NetApp’s sole discretion. Any such referenced services or features do not represent promises to deliver, commitments, or obligations of NetApp and may not be incorporated into any contract. Customers should make their purchase decisions based upon services and features that are currently generally available.
The post Instaclustr product update: December 2025 appeared first on Instaclustr.
Freezing streaming data into Apache Iceberg™—Part 1: Using Apache Kafka®Connect Iceberg Sink Connector
IntroductionEver since the first distributed system—i.e. 2 or more computers networked together (in 1969)—there has been the problem of distributed data consistency: How can you ensure that data from one computer is available and consistent with the second (and more) computers? This problem can be uni-directional (one computer is considered the source of truth, others are just copies), or bi-directional (data must be synchronized in both directions across multiple computers).
Some approaches to this problem I’ve come across in the last 8 years include Kafka Connect (for elegantly solving the heterogeneous many-to-many integration problem by streaming data from source systems to Kafka and from Kafka to sink systems, some earlier blogs on Apache Camel Kafka Connectors and a blog series on zero-code data pipelines), MirrorMaker2 (MM2, for replicating Kafka clusters, a 2 part blog series), and Debezium (Change Data Capture/CDC, for capturing changes from databases as streams and making them available in downstream systems, e.g. for Apache Cassandra and PostgreSQL)—MM2 and Debezium are actually both built on Kafka Connect.
Recently, some “sink” systems have been taking over responsibility for streaming data from Kafka into themselves, e.g. OpenSearch pull-based ingestion (c.f. OpenSearch Sink Connector), and the ClickHouse Kafka Table Engine (c.f. ClickHouse Sink Connector). These “pull-based” approaches are potentially easier to configure and don’t require running a separate Kafka Connect cluster and sink connectors, but some downsides may be that they are not as reliable or independently scalable, and you will need to carefully monitor and scale them to ensure they perform adequately.
And then there’s “zero-copy” approaches—these rely on the well-known computer science trick of sharing a single copy of data using references (or pointers), rather than duplicating the data. This idea has been around for almost as long as computers, and is still widely applicable, as we’ll see in part 2 of the blog.
The distributed data use case we’re going to explore in this 2-part blog series is streaming Apache Kafka data into Apache Iceberg, or “Freezing streaming Apache Kafka data into an (Apache) Iceberg”! In part 1 we’ll introduce Apache Iceberg and look at the first approach for “freezing” streaming data using the Kafka Connect Iceberg Sink Connector.
What is Apache Iceberg?Apache Iceberg is an open source specification open table format optimized for column-oriented workloads, supporting huge analytic datasets. It supports multiple different concurrent engines that can insert and query table data using SQL—and Iceberg is organized like, well, an iceberg!
The tip of the Iceberg is the Catalog. An Iceberg Catalog acts as a central metadata repository, tracking the current state of Iceberg tables, including their names, schemas, and metadata file locations. It serves as the “single source of truth” for a data Lakehouse, enabling query engines to find the correct metadata file for a table to ensure consistent and atomic read/write operations.
Just under the water, the next layer is the metadata layer. The Iceberg metadata layer tracks the structure and content of data tables in a data lake, enabling features like efficient query planning, versioning, and schema evolution. It does this by maintaining a layered structure of metadata files, manifest lists, and manifest files that store information about table schemas, partitions, and data files, allowing query engines to prune unnecessary files and perform operations atomically.
The data layer is at the bottom. The Iceberg data layer is the storage component where the actual data files are stored. It supports different storage backends, including cloud-based object storage like Amazon S3 or Google Cloud Storage, or HDFS. It uses file formats like Parquet or Avro. Its main purpose is to work in conjunction with Iceberg’s metadata layer to manage table snapshots and provide a more reliable and performant table format for data lakes, bringing data warehouse features to large datasets.

As shown in the above diagram, Iceberg supports multiple different engines, including Apache Spark and ClickHouse. Engines provide the “database” features you would expect, including:
- Data Management
- ACID Transactions
- Query Planning and Optimization
- Schema Evolution
- And more!
I’ve recently been reading an excellent book on Apache Iceberg (“Apache Iceberg: The Definitive Guide”), which explains the philosophy, architecture and design, including operation, of Iceberg. For example, it says that it’s best practice to treat data lake storage as immutable—data should only be added to a Data Lake, not deleted. So, in theory at least, writing infinite, immutable Kafka streams to Iceberg should be straightforward!
But because it’s a complex distributed system (which looks like a database from above water but is really a bunch of files below water!), there is some operational complexity. For example, it handles change and consistency by creating new snapshots for every modification, enabling time travel, isolating readers from writes, and supporting optimistic concurrency control for multiple writers. But you need to manage snapshots (e.g. expiring old snapshots). And chapter 4 (performance optimisation) explains that you may need to worry about compaction (reducing too many small files), partitioning approaches (which can impact read performance), and handling row-level updates. The first two issues may be relevant for Kafka, but probably not the last one. So, it looks like it’s good fit for the streaming Kafka use cases, but we may need to watch out for Iceberg management issues.
“Freezing” streaming data with the Kafka Iceberg Sink ConnectorBut Apache Iceberg is “frozen”—what’s the connection to fast-moving streaming data? You certainly don’t want to collide with an iceberg from your speedy streaming “ship”—but you may want to freeze your streaming data for long-term analytical queries in the future. How can you do that without sinking? Actually, a “sink” is the first answer: A Kafka Connect Iceberg Sink Connector is the most common way of “freezing” your streaming data in Iceberg!
Kafka Connect is the standard framework provided by Apache Kafka to move data from multiple heterogeneous source systems to multiple heterogeneous sink systems, using:
- A Kafka cluster
- A Kafka Connect cluster (running connectors)
- Kafka Connect source connectors
- Kafka topics and
- Kafka Connect Sink Connectors
That is, a highly decoupled approach. It provides real-time data movement with high scalability, reliability, error handling and simple transformations.
Here’s the Kafka Connect Iceberg Sink Connector official documentation.
It appears to be reasonably complicated to configure this sink connector; you will need to know something about Iceberg. For example, what is a “control topic”? It’s apparently used to coordinate commits for exactly-once semantics (EOS).
The connector supports fan-out (writing to multiple Iceberg tables from one topic), fan-in (writing to one Iceberg table from multiple topics), static and dynamic routing, and filtering.
In common with many technologies that you may want to use as Kafka Connect sinks, they may not all have good support for Kafka metadata. The KafkaMetadata Transform (which injects topic, partition, offset and timestamp properties) is only experimental at present.
How are Iceberg tables created with the correct metadata? If you have JSON record values, then schemas are inferred by default (but may not be correct or optimal). Alternatively, explicit schemas can be included in-line or referenced from a Kafka Schema Registry (e.g. Karapace), and, as an added bonus, schema evolution is supported. Also note that Iceberg tables may have to be manually created prior to use if your Catalog doesn’t support table auto-creation.
From what I understood about Iceberg, to use it (e.g. for writes), you need support from an engine (e.g. to add raw data to the Iceberg warehouse, create the metadata files, and update the catalog). How does this work for Kafka Connect? From this blog I discovered that the Kafka Connect Iceberg Sink connector is functioning as an Iceberg engine for writes, so there really is an engine, but it’s built into the connector.
As is the case with all Kafka Connect Sink Connectors, records are available immediately they are written to Kafka topics by Kafka producers and Kafka Connect Source Connectors, i.e. records in active segments can be copied immediately to sink systems. But is the Iceberg Sink Connector real-time? Not really! The default time to write to Iceberg is every 5 minutes (iceberg.control.commit.interval-ms) to prevent multiplication of small files—something that Iceberg(s) doesn’t/don’t like (“melting”?). In practice, it’s because every data file must be tracked in the metadata layer, which impacts performance in many ways—proliferation of small files is typically addressed by optimization and compaction (e.g. Apache Spark supports Iceberg management, including these operations).
So, unlike most Kafka Connect sink connectors, which write as quickly as possible, there will be lag before records appear in Iceberg tables (“time to freeze” perhaps)!
The systems are separate (Kafka and Iceberg are independent), records are copied to Iceberg, and that’s it! This is a clean separation of concerns and ownership. Kafka owns the source data (with Kafka controlling data lifecycles, including record expiry), Kafka Connect Iceberg Sink Connector performs the reading from Kafka and writing to Iceberg, and is independently scalable to Kafka. Kafka doesn’t handle any of the Iceberg management. Once the data has landed in Iceberg, Kafka has no further visibility or interest in it. And the pipeline is purely one way, write only – reads or deletes are not supported.
Here’s a summary of this approach to freezing streams:
- Kafka Connect Iceberg Sink Connector shares all the benefits of the Kafka Connect framework, including scalability, reliability, error handling, routing, and transformations.
- At least, JSON values are required, ideally full schemas and referenced in Karapace—but not all schemas are guaranteed to work.
- Kafka Connect doesn’t “manage” Iceberg (e.g. automatically aggregate small files, remove snapshots, etc.)
- You may have to tune the commit interval – 5 minutes is the default.
- But it does have a built-in engine that supports writing to Iceberg.
- You may need to use an external tool (e.g. Apache Spark) for Iceberg management procedures.
- It’s write-only to Iceberg. Reads or deletes are not supported
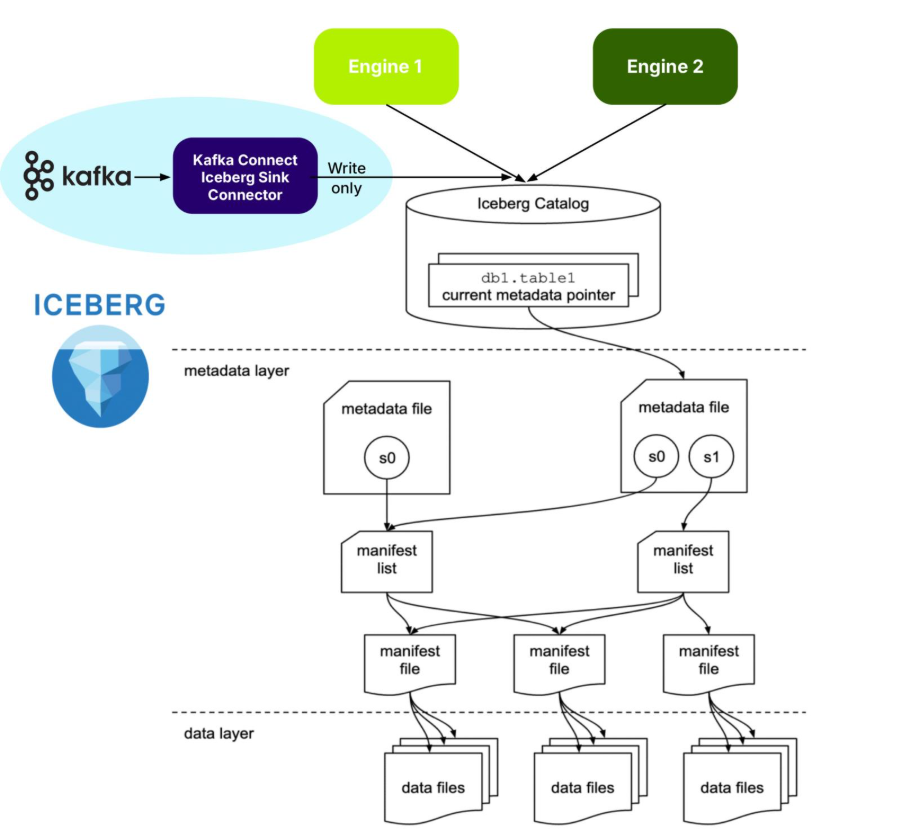
But what’s the best thing about the Kafka Connect Iceberg Sink Connector? It’s available now (as part of the Apache Iceberg build) and works on the NetApp Instaclustr Kafka Connect platform as a “bring your own connector” (instructions here).
In part 2, we’ll look at Kafka Tiered Storage and Iceberg Topics!
The post Freezing streaming data into Apache Iceberg™—Part 1: Using Apache Kafka®Connect Iceberg Sink Connector appeared first on Instaclustr.
Optimizing Cassandra Repair for Higher Node Density
This is the fourth post in my series on improving the cost efficiency of Apache Cassandra through increased node density. In the last post, we explored compaction strategies, specifically the new UnifiedCompactionStrategy (UCS) which appeared in Cassandra 5.
- Streaming Throughput
- Compaction Throughput and Strategies
- Repair (you are here)
- Query Throughput
- Garbage Collection and Memory Management
- Efficient Disk Access
- Compression Performance and Ratio
- Linearly Scaling Subsystems with CPU Core Count and Memory
Now, we’ll tackle another aspect of Cassandra operations that directly impacts how much data you can efficiently store per node: repair. Having worked with repairs across hundreds of clusters since 2012, I’ve developed strong opinions on what works and what doesn’t when you’re pushing the limits of node density.
Building easy-cass-mcp: An MCP Server for Cassandra Operations
I’ve started working on a new project that I’d like to share, easy-cass-mcp, an MCP (Model Context Protocol) server specifically designed to assist Apache Cassandra operators.
After spending over a decade optimizing Cassandra clusters in production environments, I’ve seen teams consistently struggle with how to interpret system metrics, configuration settings, schema design, and system configuration, and most importantly, how to understand how they all impact each other. While many teams have solid monitoring through JMX-based collectors, extracting and contextualizing specific operational metrics for troubleshooting or optimization can still be cumbersome. The good news is that we now have the infrastructure to make all this operational knowledge accessible through conversational AI.
easy-cass-stress Joins the Apache Cassandra Project
I’m taking a quick break from my series on Cassandra node density to share some news with the Cassandra community: easy-cass-stress has officially been donated to the Apache Software Foundation and is now part of the Apache Cassandra project ecosystem as cassandra-easy-stress.
Why This Matters
Over the past decade, I’ve worked with countless teams struggling with Cassandra performance testing and benchmarking. The reality is that stress testing distributed systems requires tools that can accurately simulate real-world workloads. Many tools make this difficult by requiring the end user to learn complex configurations and nuance. While consulting at The Last Pickle, I set out to create an easy to use tool that lets people get up and running in just a few minutes
Compaction Strategies, Performance, and Their Impact on Cassandra Node Density
This is the third post in my series on optimizing Apache Cassandra for maximum cost efficiency through increased node density. In the first post, I examined how streaming operations impact node density and laid out the groundwork for understanding why higher node density leads to significant cost savings. In the second post, I discussed how compaction throughput is critical to node density and introduced the optimizations we implemented in CASSANDRA-15452 to improve throughput on disaggregated storage like EBS.
Cassandra Compaction Throughput Performance Explained
This is the second post in my series on improving node density and lowering costs with Apache Cassandra. In the previous post, I examined how streaming performance impacts node density and operational costs. In this post, I’ll focus on compaction throughput, and a recent optimization in Cassandra 5.0.4 that significantly improves it, CASSANDRA-15452.
This post assumes some familiarity with Apache Cassandra storage engine fundamentals. The documentation has a nice section covering the storage engine if you’d like to brush up before reading this post.
How Cassandra Streaming, Performance, Node Density, and Cost are All related
This is the first post of several I have planned on optimizing Apache Cassandra for maximum cost efficiency. I’ve spent over a decade working with Cassandra and have spent tens of thousands of hours data modeling, fixing issues, writing tools for it, and analyzing it’s performance. I’ve always been fascinated by database performance tuning, even before Cassandra.
A decade ago I filed one of my first issues with the project, where I laid out my target goal of 20TB of data per node. This wasn’t possible for most workloads at the time, but I’ve kept this target in my sights.
Cassandra 5 Released! What's New and How to Try it
Apache Cassandra 5.0 has officially landed! This highly anticipated release brings a range of new features and performance improvements to one of the most popular NoSQL databases in the world. Having recently hosted a webinar covering the major features of Cassandra 5.0, I’m excited to give a brief overview of the key updates and show you how to easily get hands-on with the latest release using easy-cass-lab.
You can grab the latest release on the Cassandra download page.
easy-cass-lab v5 released
I’ve got some fun news to start the week off for users of easy-cass-lab: I’ve just released version 5. There are a number of nice improvements and bug fixes in here that should make it more enjoyable, more useful, and lay groundwork for some future enhancements.
- When the cluster starts, we wait for the storage service to
reach NORMAL state, then move to the next node. This is in contrast
to the previous behavior where we waited for 2 minutes after
starting a node. This queries JMX directly using Swiss Java Knife
and is more reliable than the 2-minute method. Please see
packer/bin-cassandra/wait-for-up-normalto read through the implementation. - Trunk now works correctly. Unfortunately, AxonOps doesn’t support trunk (5.1) yet, and using the agent was causing a startup error. You can test trunk out, but for now the AxonOps integration is disabled.
- Added a new repl mode. This saves keystrokes and provides some
auto-complete functionality and keeps SSH connections open. If
you’re going to do a lot of work with ECL this will help you be a
little more efficient. You can try this out with
ecl repl. - Power user feature: Initial support for profiles in AWS regions
other than
us-west-2. We only provide AMIs forus-west-2, but you can now set up a profile in an alternate region, and build the required AMIs usingeasy-cass-lab build-image. This feature is still under development and requires using aneasy-cass-labbuild from source. Credit to Jordan West for contributing this work. - Power user feature: Support for multiple profiles. Setting the
EASY_CASS_LAB_PROFILEenvironment variable allows you to configure alternate profiles. This is handy if you want to use multiple regions or have multiple organizations. - The project now uses Kotlin instead of Groovy for Gradle configuration.
- Updated Gradle to 8.9.
- When using the list command, don’t show the alias “current”.
- Project cleanup, remove old unused pssh, cassandra build, and async profiler subprojects.
The release has been released to the project’s GitHub page and to homebrew. The project is largely driven by my own consulting needs and for my training. If you’re looking to have some features prioritized please reach out, and we can discuss a consulting engagement.
easy-cass-lab updated with Cassandra 5.0 RC-1 Support
I’m excited to announce that the latest version of easy-cass-lab now supports Cassandra 5.0 RC-1, which was just made available last week! This update marks a significant milestone, providing users with the ability to test and experiment with the newest Cassandra 5.0 features in a simplified manner. This post will walk you through how to set up a cluster, SSH in, and run your first stress test.
For those new to easy-cass-lab, it’s a tool designed to streamline the setup and management of Cassandra clusters in AWS, making it accessible for both new and experienced users. Whether you’re running tests, developing new features, or just exploring Cassandra, easy-cass-lab is your go-to tool.
easy-cass-lab now available in Homebrew
I’m happy to share some exciting news for all Cassandra enthusiasts! My open source project, easy-cass-lab, is now installable via a homebrew tap. This powerful tool is designed to make testing any major version of Cassandra (or even builds that haven’t been released yet) a breeze, using AWS. A big thank-you to Jordan West who took the time to make this happen!
What is easy-cass-lab?
easy-cass-lab is a versatile testing tool for Apache Cassandra. Whether you’re dealing with the latest stable releases or experimenting with unreleased builds, easy-cass-lab provides a seamless way to test and validate your applications. With easy-cass-lab, you can ensure compatibility and performance across different Cassandra versions, making it an essential tool for developers and system administrators. easy-cass-lab is used extensively for my consulting engagements, my training program, and to evaluate performance patches destined for open source Cassandra. Here are a few examples:
Cassandra Training Signups For July and August Are Open!
I’m pleased to announce that I’ve opened training signups for Operator Excellence to the public for July and August. If you’re interested in stepping up your game as a Cassandra operator, this course is for you. Head over to the training page to find out more and sign up for the course.
Streaming My Sessions With Cassandra 5.0
As a long time participant with the Cassandra project, I’ve witnessed firsthand the evolution of this incredible database. From its early days to the present, our journey has been marked by continuous innovation, challenges, and a relentless pursuit of excellence. I’m thrilled to share that I’ll be streaming several working sessions over the next several weeks as I evaluate the latest builds and test out new features as we move toward the 5.0 release.
Streaming Cassandra Workloads and Experiments
Streaming
In the world of software engineering, especially within the realm of distributed systems, continuous learning and experimentation are not just beneficial; they’re essential. As a software engineer with a focus on distributed systems, particularly Apache Cassandra, I’ve taken this ethos to heart. My journey has led me to not only explore the intricacies of Cassandra’s distributed architecture but also to share my experiences and findings with a broader audience. This is why my YouTube channel has become an active platform where I stream at least once a week, engaging with viewers through coding sessions, trying new approaches, and benchmarking different Cassandra workloads.
Live Streaming On Tuesdays
As I promised in December, I redid my presentation from the Cassandra Summit 2023 on a live stream. You can check it out at the bottom of this post.
Going forward, I’ll be live-streaming on Tuesdays at 10AM Pacific on my YouTube channel.
Next week I’ll be taking a look at tlp-stress, which is used by the teams at some of the biggest Cassandra deployments in the world to benchmark their clusters. You can find that here.
Cassandra Summit Recap: Performance Tuning and Cassandra Training
Hello, friends in the Apache Cassandra community!
I recently had the pleasure of speaking at the Cassandra Summit in San Jose. Unfortunately, we ran into an issue with my screen refusing to cooperate with the projector, so my slides were pretty distorted and hard to read. While the talk is online, I think it would be better to have a version with the right slides as well as a little more time. I’ve decided to redo the entire talk via a live stream on YouTube. I’m scheduling this for 10am PST on Wednesday, January 17 on my YouTube channel. My original talk was done in 30 minute slot, this will be a full hour, giving plenty of time for Q&A.
Cassandra Summit, YouTube, and a Mailing List
I am thrilled to share some significant updates and exciting plans with my readers and the Cassandra community. As we draw closer to the end of the year, I’m preparing for an important speaking engagement and mapping out a year ahead filled with engaging and informative activities.
Cassandra Summit Presentation: Mastering Performance Tuning
I am honored to announce that I will be speaking at the upcoming Cassandra Summit. My talk, titled “Cassandra Performance Tuning Like You’ve Been Doing It for Ten Years,” is scheduled for December 13th, from 4:10 pm to 4:40 pm. This session aims to equip attendees with advanced insights and practical skills for optimizing Cassandra’s performance, drawing from a decade’s worth of experience in the field. Whether you’re new to Cassandra or a seasoned user, this talk will provide valuable insights to enhance your database management skills.
Uncover Cassandra's Throughput Boundaries with the New Adaptive Scheduler in tlp-stress
Introduction
Apache Cassandra remains the preferred choice for organizations seeking a massively scalable NoSQL database. To guarantee predictable performance, Cassandra administrators and developers rely on benchmarking tools like tlp-stress, nosqlbench, and ndbench to help them discover their cluster’s limits. In this post, we will explore the latest advancements in tlp-stress, highlighting the introduction of the new Adaptive Scheduler. This brand-new feature allows users to more easily uncover the throughput boundaries of Cassandra clusters while remaining within specific read and write latency targets. First though, we’ll take a brief look at the new workload designed to stress test the new Storage Attached Indexes feature coming in Cassandra 5.
AxonOps Review - An Operations Platform for Apache Cassandra
Note: Before we dive into this review of AxonOps and their offerings, it’s important to note that this blog post is part of a paid engagement in which I provided product feedback. AxonOps had no influence or say over the content of this post and did not have access to it prior to publishing.
In the ever-evolving landscape of data management, companies are constantly seeking solutions that can simplify the complexities of database operations. One such player in the market is AxonOps, a company that specializes in providing tooling for operating Apache Cassandra.
Benchmarking Apache Cassandra with tlp-stress
This post will introduce you to tlp-stress, a tool for benchmarking Apache Cassandra. I started tlp-stress back when I was working at The Last Pickle. At the time, I was spending a lot of time helping teams identify the root cause of performance issues and needed a way of benchmarking. I found cassandra-stress to be difficult to use and configure, so I ended up writing my own tool that worked in a manner that I found to be more useful. If you’re looking for a tool to assist you in benchmarking Cassandra, and you’re looking to get started quickly, this might be the right tool for you.
Back to Consulting!
Saying “it’s been a while since I wrote anything here” would be an understatement, but I’m back, with a lot to talk about in the upcoming months.
First off - if you’re not aware, I continued writing, but on The Last Pickle blog. There’s quite a few posts there, here are the most interesting ones:
- 14 Things To Do When Setting Up a New Cassandra Cluster
- Apache Cassandra Performance Tuning - Compression with Mixed Workloads
- Garbage Collection Tuning for Apache Cassandra
- Analyzing Cassandra Performance with Flame Graphs
- Cassandra Time Series Data Modeling For Massive Scale
Now the fun part - I’ve spent the last 3 years at Apple, then Netflix, neither of which gave me much time to continue my writing. As of this month, I’m officially no longer at Netflix and have started Rustyrazorblade Consulting!
Building a 100% ScyllaDB Shard-Aware Application Using Rust
Building a 100% ScyllaDB Shard-Aware Application Using Rust
I wrote a web transcript of the talk I gave with my colleagues Joseph and Yassir at [Scylla Su...
Learning Rust the hard way for a production Kafka+ScyllaDB pipeline
Learning Rust the hard way for a production Kafka+ScyllaDB pipeline
This is the web version of the talk I gave at [Scylla Summit 2022](https://www.scyllad...
On Scylla Manager Suspend & Resume feature
On Scylla Manager Suspend & Resume feature
!!! warning "Disclaimer" This blog post is neither a rant nor intended to undermine the great work that...
Renaming and reshaping Scylla tables using scylla-migrator
We have recently faced a problem where some of the first Scylla tables we created on our main production cluster were not in line any more with the evolved s...
Python scylla-driver: how we unleashed the Scylla monster's performance
At Scylla summit 2019 I had the chance to meet Israel Fruchter and we dreamed of working on adding **shard...